License
Copyright 2012-2023 Machine Learning and Language Processing (MLLP) research group.
Licensed under the Apache License, Version 2.0.
The transLectures-UPV Platform (TLP) includes software developed at the Universitat Politècnica de València (UPV) by the MLLP research group as part of the transLectures EU project until TLP Version 1.0.1.
1. Introduction
The transLectures-UPV Platform (TLP) consists of a set of software tools that enable the integration of advanced Automatic Speech Recognition (ASR), Machine Translation (MT) and Text-To-Speech Systhesis (TTS) technologies into large video repositories and Massive Open Online Courses (MOOCs) platforms. These technologies are used to generate automatic multilingual subtitles and (synthesized) audiotracks of audio and video files, as well as to generate automatic translations of text/HTML documents. TLP also includes web-based tools to view and easily correct transcription and translation errors in order to generate perfect outputs. In addition, TLP also brings support to multilingual web translation using MT technology.
It was developed up to Version 1.0.1 by the MLLP research group from the Universitat Politècnica de València (UPV) as part of the EU research project transLectures. After the end of transLectures, TLP is still being maintained by the MLLP research group from version 1.1.
2. Getting Started
In this section we will give a brief overview of the transLectures-UPV Platform (TLP), describing the workflows involved when integrating Automatic Speech Recognition (ASR), Machine Translation (MT) and Text-To-Speech Systhesis (TTS) technologies into large media repositories, MOOC platforms and websites with the aid of this platform.
2.1. TLP Overview
TLP is a self-contained piece of software that includes everything that is needed in order to integrate transcription, translation and speech synthesis technologies into large media repositories, MOOC platforms and/or websites.
The main features of TLP are the following:
-
Easy integration of ASR, MT and TTS technologies: TLP provides a framework via the Ingest Service in which custom ASR, MT and TTS systems can be easily integrated into the platform to provide automatic subtitles, document translations, and synthesised text-to-speech audio tracks.
-
Exploitation of media-related resources: Topic adaptation techniques for ASR are supported by TLP (i.e. exploitation of text extracted from suplied media slides, related documents, etc.)
-
Support to grid computing: TLP has been developed expressly to take advantage of computer clusters in order to parallelize at maximum transcription, translation, and text-to-speech processes.
-
Ergonomic solution for subtitle and translation editing: TLP includes a web-based software tool, called the TLP Media Player, that can be used to review transcriptions and subtitles respectively for audio/video objects with ease and comfort; as well as a third web-based tool called the TLP Translation Editor to review text document translations.
-
Support to collaborative subtitling/translation: TLP enables collaborative video subtitling and document translation by managing edit sessions and keeping track of all user editions made on subtitle and translation files. Changes can be postponed to be reviewed by authors, who can later review these changes to accept or reject them.
-
Automated postprocess triggered by user interactions: Whenever a transcription or translation is edited, time alignments at the word level for transcriptions, automatic translations, and automatic synthesised audio tracks are re-generated; among other actions. This feature is directly managed by the Postprocessor module.
-
Support to multilingual web translation: MT technology can be used used as to translate static and dynamic web pages or web sites in a very straightforward manner trough the Web Translation Plugin and the Web Translation Editor.
-
Extensive and powerful public API: TLP offers a complete API that makes very easy the integration process between TLP and remote video repositories, MOOC platforms, institutions, companies, etc.
-
Based on open-source tools and libraries: All software tools included in TLP are entirely based on open-source languages and libraries.
-
Publicly released as open-source software: Successive versions of TLP have been publicly released under the open-source Apache License 2.0.
Its main components are the Database, the Web Service, the Ingest Service, the Media Player, the Translation Editor, the Web Translation Plugin and the Web Translation Editor, each of which are described in their corresponding sections. In addition, TLP features the Postprocessor module to perform automated actions on the basis of user interaction, as well as several Client Tools.
The figure below shows the main components of TLP and a simplification of the interactions between them.

2.2. Use Cases
In this section we show basic use cases of TLP in three different scenarios: on large media repositories, on MOOC platforms, and on on-line websites.
2.2.1. TLP for large media repositories
We have defined three use cases to illustrate the main ways a large media repository and its users can interact with TLP:
-
A new recording from the media repository is uploaded to TLP for the generation of automatic subtitles and audio tracks.
-
A user plays a media file with subtitles from the media repository’s website.
-
A user corrects subtitle errors (transcription or translation).

A lecturer/speaker records a new lecture/media in a recording studio, in a classroom, or during a conference. To get this video transcribed and translated into several languages the recorded media file plus other metadata are sent to the TLP Web Service via the /speech/ingest interface.
The TLP Ingest Service reads this upload and launches the required transcription, translation and/or speech synthesis processes. During this stage, the client (in this case, the remote media repository) can check at any time the progress of the upload using the /speech/status endpoint of the Web Service.
Finally, the Ingest Service creates a new media record in the Database and stores all media, subtitles, and synthesized audiotrack files.

A user browses the media repository’s catalogue and selects the media he or she wants to watch/listen using the repository’s media player. The user can watch the selected media with subtitles in different languages, or even listen to it in another language using automatically synthesized audio tracks where available.
To get the list of all subtitle languages available, the repository’s media player sends a request to the /speech/langs interface of the TLP’s Web Service, displaying to the user the language availability.
As the user selects the desired subtitle language, the repository’s media player calls the /speech/get endpoint to download the corresponding subtitle file in the required format (srt, vtt, dfxp, etc.), which is immediately processed and displayed in the media player.
A similar procedure is followed when the user requests a synthesized audio track, but in this case the media player makes use of the /speech/audiotrack interface.
.")
A user (or a lecturer), while playing a media file with subtitles (as shown above in use case 2), notices that the displayed subtitles contain some errors and decides to correct them. The repository’s media player redirects somehow the user to the TLP Media Player, that offers an ergonomic and efficient interface for subtitle editing.
Any corrections made by the user are sent back to the Web Service via the /speech/mod interface and appended to the subtitles file, or left for revision, depending on the user’s confidence. All subtitle edits are kept so that at any time a user with special permissions can browse the edition history and recover previous editions.
In case the subtitle file is updated, automatic translations and synthesized audio tracks are automatically re-generated using user corrections.
2.2.2. TLP for MOOC platforms
We have defined three use cases to illustrate the main ways a MOOC platform can interact with TLP:
-
A new MOOC is added to the platform, and automatic subtitles for videos as well as automatic translations for text contents are requested.
-
MOOC teachers review video subtitles and translations of text contents.
-
Video subtitles and translated text contents are imported into the MOOC platform.

A MOOC teacher or manager adds a new MOOC to the platform’s catalogue, and requests to translate all MOOC contents into several languages. Automatically, the MOOC Platform identifies all video and text contents and uploads them to the TLP server using the /speech/ingest and /text/ingest API interfaces respectively from the Web Service.
The Ingest Service reads these uploads and launches the required transcription, translation and/or speech synthesis processes. During this stage, the client (in this case, the remote media repository) can check at any time the progress of the upload using the /speech/status and /text/status endpoints.
Finally, the Ingest Service creates a new media record in the Database and stores all media, subtitles, synthesized audiotrack, documents and translations.

After a successful generation of automatic subtitles and translations, the MOOC teacher wants to review these outputs, in order to amend possible transcription and/or translation errors.
The MOOC platform allows the teacher to use the TLP Media Player to review video subtitles and the TLP Translation Editor to amend translation errors of text contents. This can be done by embedding them in the MOOC platform or by redirecting the teacher to a specific URL.
Any corrections made by the teacher are sent back to the Web Service via the /speech/mod or /text/mod interfaces. All editions are kept so that at any time a user with special permissions can browse the edition history and recover previous editions. In case a subtitle or translations file is updated, automatic translations and synthesized audio tracks, when applicable, are automatically re-generated by the Ingest Service using user corrections.
It must be noted that TLP brings to MOOC platforms the possibility of setting up a subtitle and translation editing framework under a collaborative scenario in which MOOC participants can carry out the process of revision with or without admin supervision.

The MOOC teacher/manager wants to import subtitles and translations for all course contents to the MOOC platform in order to bring them to students. Automatically, the MOOC platform retrieves all video subtitles and translations from text contents using the /speech/get and /text/get API interfaces respectively. Subtitles and translations are stored in the MOOC platform database in order to make them available for the students. This operation could be executed every time any subtitles and/or translations from the MOOC course are modified.
2.2.3. TLP for multilingual web translation
We have defined three use cases to illustrate the main ways a website can interact with TLP for multilingual web translation:
-
An API client registers a new website into TLP to make it multilingual.
-
A user enters into the website and requests a translated version.
-
The website admin decides to correct translation errors.
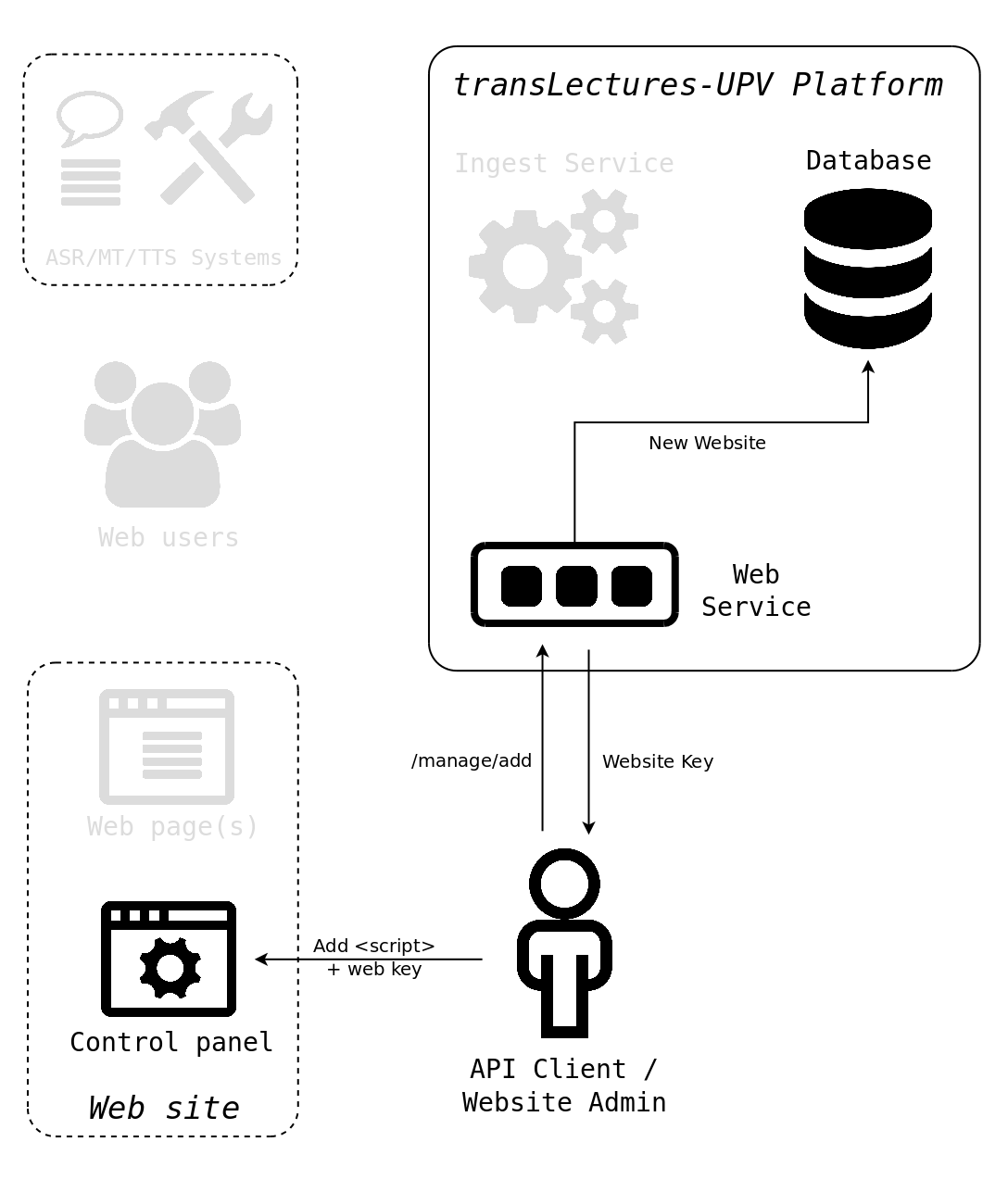
An API client wants to make multilingual a new webpage. To do so, first, the
client registers the webpage into TLP by using the /web/manage/add
API interface of the TLP Web Service. This interface returns a
unique website key, used to identify the website in further transactions. Then,
the API client integrates the TLP’s Web Translation plugin into the
website by just adding a proper <script> HTML5 element in the header of all
website’s pages. The <script> tag basically commands to the web browser to
call the /web/getjs interface using the website key as parameter
to get and load the specific Web Translation plugin generated for that website.
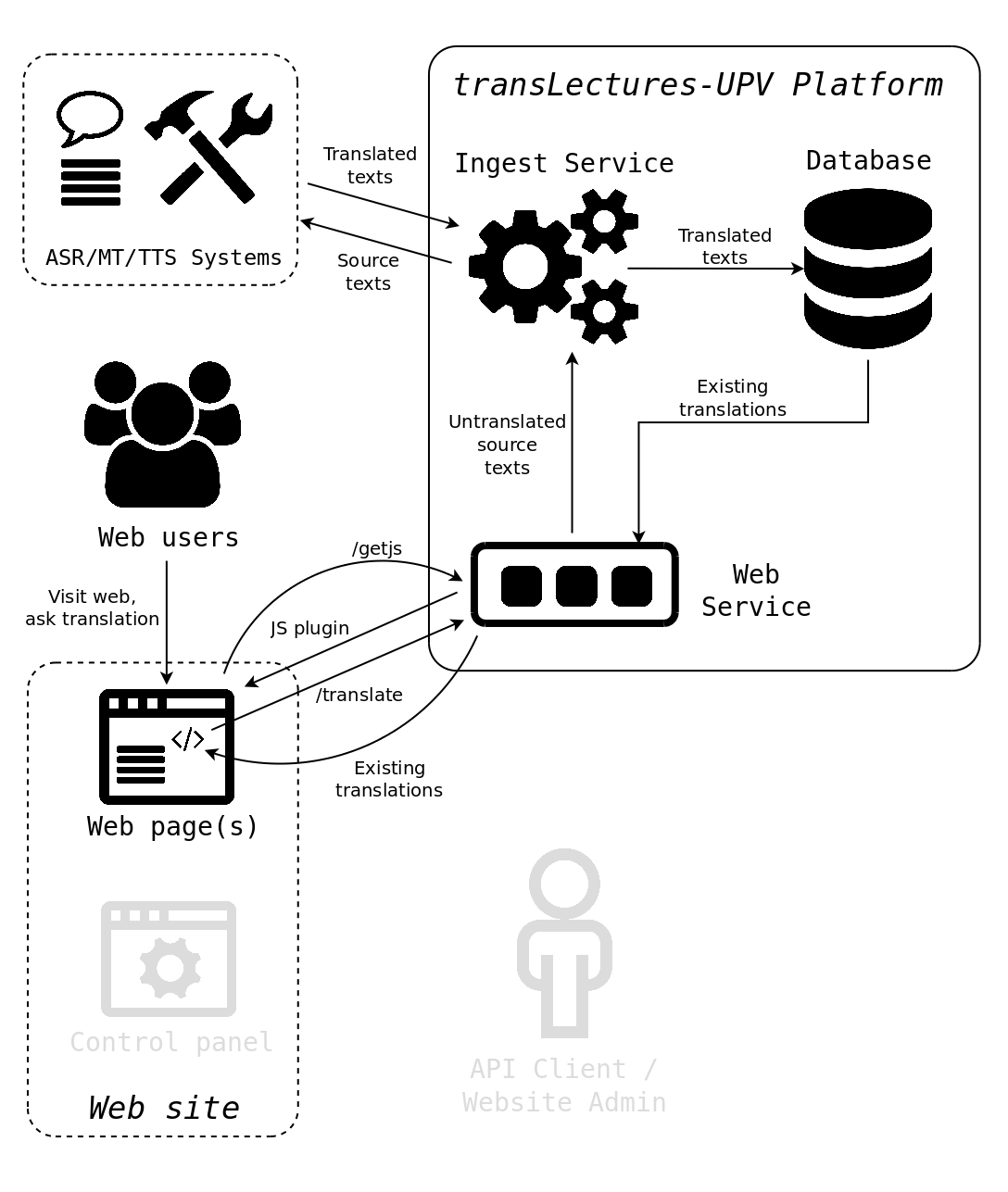
A user visits the website using his/her web browser and requests a translated version of the webpage in a given language. First of all, the web browser calls the /web/getjs interface to get and load the specific Web Translation plugin generated for that website. Then, as soon as the webpage contents are rendered by the browser, the plugin parses the whole HTML document, locating all text contents and sending them to the /web/translate interface in order to retrieve their translations into the language requested by the user. The Web Service then returns to the browser the available translations for the given texts, displaying them to the user. It might be that some text contents have not been translated yet, for instance, when a webpage is parsed for the first time by the web translation plugin, or when the original text contents have been modified. In both cases, the untranslated source texts are sent to the Ingest Service to generate their translations. After a while, these translations are stored into the Database in order to make them available in future requests.
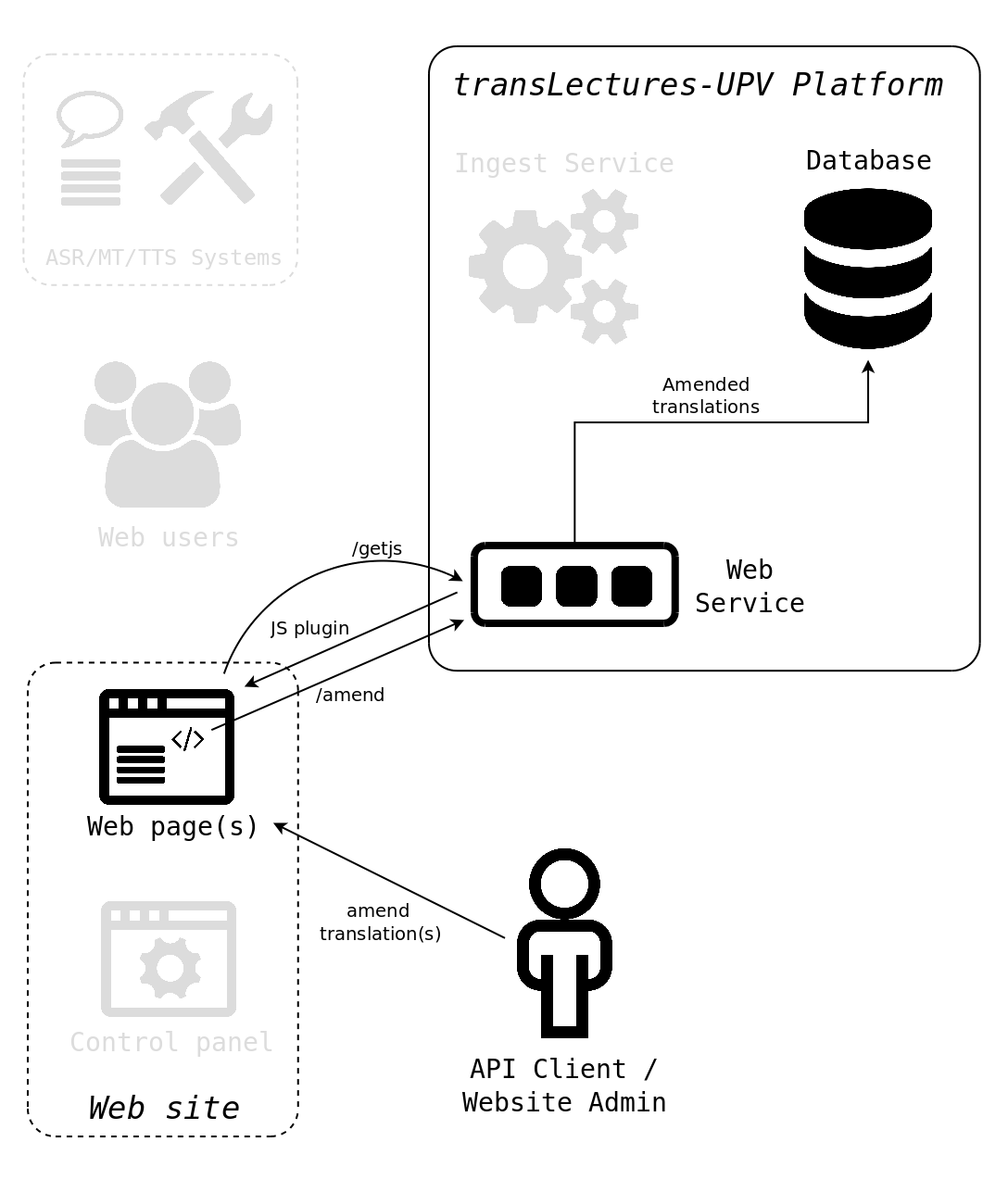
The website’s admin, after visiting a web page (as depicted in use case 2), notices a translation error and decides to amend it. After pressing a specific combination of keys, the Web Translation plugin shows the translation editor interface. Then, the admin user clicks to the corresponding text node, amends the translation, and confirms the correction. The plugin then sends back to the server the corrected text by calling the /web/amend interface. The amended text is finally stored into the Database, making it available in future requests.
Alternatively, admins can review the whole website’s translations anywhere using the embbedable TLP Web Translation Editor.
3. Database
The TLP Database is a SQL-based relational database which stores all the data required for the Web Service and the Ingest Service. The main entities stored in the Database are the following:
-
Videos/Audios: All the information related to a specific audio or video is stored in the database, including language, duration, title, keywords and category. An external ID, provided by the client is used to identify the media object in all transactions performed between the client and the API.
-
Speakers: Information about the speaker/lecturer can be used by the ASR system to adapt the underlying models to the unique characteristics of the given speaker and, therefore, improve the quality of the resulting subtitles.
-
Subtitles: All subtitles automatically generated by the Ingest Service are stored in DFXP format into the database and retrieved by the client via the Web Service.
-
Audiotracks: As in the case of subtitles, automatically synthesized audio tracks from translated subtitles are also stored in the database.
-
Documents: Similarly to video and audio entities, text documents are stored as well along with metadata such as document format, sentences, words, language, etc.
-
Translations: Again, similarly to subtitles objects, translations in the original document format, as well as in an internal XML format (DTLX format), are stored in the database.
-
Websites: Metadata of every website or webpage to be translated, as well as all source and translated texts.
-
Uploads: Every time an /ingest operation is performed, a new upload entry is stored in the database to track its progress.
TLP also needs to store data outside the relational database (in the filesystem of the TLP Server). In TLP are defined several data sources,
and their root directories or mount points have to be registered in the mount_points table of the database:
-
Language Processing modules: Root directory of all language processing modules to integrated into the Ingest Service (
systemskey). -
Video/audio objects:
-
Media files: Root directory of media files, such as video, audio, slides, thumbnail files (
mediakey). -
Subtitle files: Root directory of subtitle files (
transcriptionskey). -
Uploads: Root directory for the uploaded objects and temporal files (
uploadskey). -
Alignments: Root directory for the temporal files of text-to-speech alignment processes (
valign_uploadskey).
-
-
Text objects:
-
Documents: Root directory of all text document files (
text_documentskey). -
Uploads: Root directory for the uploaded objects and temporal files (
text_uploadskey).
-
-
Web objects:
-
Uploads: Root directory for temporal files (
web_uploadskey).
-
4. Web Service
The Web Service is the API interface for exchanging information and data between the client and the transLectures-UPV Platform. It also enables the viewing and editing capabilities of the TLP Media Player and the TLP Translation Editor, as well as the website translation features. The Web Service defines a wide set of API HTTP interfaces to allow for the full integration between TLP and the remote media repository, MOOC Platform, or website.
The Web Service implements thre sub-APIs for the three main classes of objects than can be processed by TLP:
/speech and /text sub-APIs feature very similar interfaces and specifications.
The Web Service requires an specific scheme for user authentication, please refer to API User Authentication for more information.
In addition, TLP offers several tools and libraries to interact with this API; you will find more information about them in the Client Tools Section.
If you decide to develop you own API client, we recommend you to read our API Technical Preface. Also, a detailed description of all API interfaces can be found in here for the /speech sub-API, here for the /text sub-API, and here for the /web sub-API.
4.1. /speech: API Interfaces for audio/video transcription and translation
Please note that all the following interfaces will share a common prefix: /speech.
|
/ingest
|
Upload media (audio/video) files and any attachments and metadata to the TLP Server for automatic multilingual subtitling and speech synthesis. |
|
/uploadslist
|
Get a list of all the user’s uploads. |
|
/status
|
Check the current status of a specific upload ID. |
|
/systems
|
Get a list of all available Speech Recognition, Machine Translation, Subtitle Postprocessing, and Text-To-Speech Systems that can be applied to transcribe, translate, and synthesize a media file. |
|
/list
|
Get a list of all existing audio and videos in the Database. |
|
/list_fullinfo
|
Get a list of all existing audios and videos in the TLP Database, plus their metadata, captions available, and media file locations. |
|
/metadata
|
Get metadata and media file locations for a given media ID. |
|
/langs
|
Get a list of all subtitle and audiotrack languages available for a given media ID. |
|
/get
|
Download the current subtitle file for a given media ID and language. |
|
/getmod
|
Get subtitle modifications in JSON format of a given media and session ID. |
|
/audiotrack
|
Download an audiotrack file for a given media ID and language. |
|
/active_sessions
|
Returns information about active edition sessions involving a particular media ID. |
|
/start_session
|
Starts an edition session to send and commit modifications of a subtitles file. |
|
/session_status
|
Returns the current status of the given session ID. |
|
/mod
|
Send and commit subtitle corrections under an edit session. |
|
/mod_scenes
|
Send and commit scene changes corrections under an edit session. |
|
/end_session
|
Ends an open edition session, and depending on the confidence of the user, editions are directly stored in the corresponding subtitles files or left for revision. |
|
/lock
|
Allow/disallow regular users to send subtitles modifications for an specific Media ID. |
|
/edit_history
|
Returns a list of all edit sessions that involved an specific media ID. |
|
/revisions
|
Returns a list of all edit sessions for all API user’s media files that are pending to be revised. |
|
/mark_revised
|
Mark/unmark as revised an specific edit session ID, typically from another Session ID on the TLP Media Player. |
|
/accept
|
Accept modifications of one or more pending edit sessions without having to revise them. Modifications are commited into the corresponding subtitles files. |
|
/reject
|
Reject modifications of one or more pending edit sessions without having to revise them. |
4.2. /text: API Interfaces for text/document translation
Please note that all the following interfaces will share a common prefix: /text.
|
/ingest
|
Upload document (text/document) files and metadata to the TLP Server to be automatically translated. |
|
/uploadslist
|
Get a list of all the user’s uploads. |
|
/status
|
Check the current status of a specific upload ID. |
|
/systems
|
Get a list of all available Machine Translation systems that can be applied to translate a document file. |
|
/list
|
Get a list of all existing documents in the Database. |
|
/metadata
|
Get metadata for a given document ID. |
|
/langs
|
Get a list of all language translations available for a given document ID. |
|
/get
|
Download the latest version of the translated document file for a given document ID and language. |
|
/start_session
|
Starts an edition session to send and commit modifications of a translation file. |
|
/session_status
|
Returns the current status of the given session ID. |
|
/mod
|
Send and commit translation corrections under an edit session. |
|
/end_session
|
Ends an open edition session, and depending on the confidence of the user, editions are directly stored in the corresponding translation files or left for revision. |
|
/lock
|
Allow/disallow regular users to send modifications for an specific document ID. |
|
/edit_history
|
Returns a list of all edit sessions that involved an specific document ID. |
|
/revisions
|
Returns a list of all edit sessions for all API user’s document files that are pending to be revised. |
|
/mark_revised
|
Mark/unmark as revised an specific edit session ID, typically from another Session ID on the TLP Translation Editor. |
|
/accept
|
Accept modifications of one or more pending edit sessions without having to revise them. Modifications are commited into the corresponding translation files. |
|
/reject
|
Reject modifications of one or more pending edit sessions without having to revise them. |
4.3. /web: API Interfaces for multilingual web translation
Please note that all the following interfaces will share a common prefix: /web.
|
/manage
|
Features four sub-interfaces to list, add, edit and delete websites. |
|
/systems
|
Get a list of all available Machine Translation systems that can be applied to translate a document file. |
|
/getjs
|
Returns a JavaScript plugin that enables web translation on web browsers. |
|
/translate
|
Requests translations of a given set of texts, sending part or all of them to translate if no translations are available yet. |
|
/amend
|
Send user corrections of translated texts. |
|
/editor
|
Features three sub-interfaces: /langs, /get and /mod. |
4.4. API User Authentication
The Web Service implements a custom API user authentication system based on authentication tokens. Every API call (except for those of the /web sub-API to be used by web browsers) must include a valid authentication token in order to authenticate the API user. TLP offers two different authentication methods:
-
Secret Key: An API user authentication token, associated to the user account, is provided to the Web Service. This token is valid for user authentication on all API interfaces. This is the recommended authentication method for direct client to server API calls.
-
Request Key: A lifetime-limited request-dependent authentication token is provided to the Web Service. This token is valid for user authentication only on a reduced set of API interfaces and for a limited period of time. This authentication method should be used in case the use of the secret key as an authentication token could be exposed or revealed to third-parties, for instance when a user belonging to the API client organisation is using the TLP Media Player or the TLP Translation Editor to edit a subtitle file or translation file, respectively.

The figure above shows a typical integration scenario between TLP and the remote media repository, in which the Secret Key authentication method is used for all direct API calls between both parts, whilst the alternative Request Key method is used to generate TLP Media Player URLs that will be followed by the repository’s users to review media subtitles. In this latter case, the Request Key is the authentication token used in all API calls between the Player and the Web Service.
For further information and technical details, please refer to the Preface of the Web Service’s API Documentation.
5. Media Player
The TLP Media Player is an HTML5 media player which allows users to review and modify media subtitles of different languages with ease. The Player provides a highly ergonomic editing interface, optimized to reduce user effort.

The TLP Media Player can be called externally/embedded using a valid URL. For further technical information, please refer to the Calling the TLP Media Player Annex.
6. Translation Editor
The TLP Translation Editor is an HTML5 software which allows users to review and modify document translations with ease. The Editor provides a highly ergonomic editing interface, optimized to reduce user effort.

The TLP Translation Editor can be called externally/embedded using a valid URL. For further technical information, please refer to the Calling the TLP Translation Editor Annex.
7. Web Translation Plugin
TLP features a web translation plugin that allows API users to automatically translate their websites directly from the web browser, that is, from the client side.
To integrate the TLP’s web translation plugin into a website:
-
Include the TLP’s Javascript plugin in the website header using the /getjs interface. I.e:
<header> <script src="http://my-tlp-server.com/api/web/getjs?key=MY_WEBSITE_KEY"></script> </header>
-
Translated contents for any website page will be accessible by adding
#lang=LANG_CODE(i.e.#lang=es) to the URL. -
Pressing
Ctrl+Alt+Ewill enable the translation editor to amend automatic translations. The plugin will request the API user’s password to grant such permission.

Alternatively, admins can review the whole website’s translations anywhere using the embbedable TLP Web Translation Editor.
8. Web Translation Editor
The TLP Web Translation Editor is an HTML5 software which allows users to review and modify all translations for a single website with ease. It can be used as an alternative to the Web Translation Plugin. The main differences to the Web Translation Plugin are:
-
All text translations are accessed at once, avoiding the navigation through the translated website.
-
Can be integrated as an external tool. This for example can be used by web masters to enable other users to review and modify the translations.

The TLP Web Translation Editor can be called externally/embedded using a valid URL. For further technical information, please refer to the Calling the TLP Web Translation Editor Annex.
9. Ingest Service
The Ingest Service is the service devoted to process video/audio and text/document files uploaded via the /speech/ingest and the /text/ingest interfaces of the Web Service, respectively. It also carries out the process of text-to-speech alignment to recover time aligments at the word level for manually reviewed transcripts.
The Ingest Service checks periodically (typically every minute) whether new uploads are awaiting to be processed, also checking if the ongoing uploads are progressing correctly or have failed. The uploads table of the Database is used to keep track of the status of every upload.
Please note that in the case of multilingual web translation, text contents to be translated are automatically gathered and sent to the Ingest Service by the Postprocessor module. Similarly for the case of text-to-speech alignment, the Postprocessor checks whether there exist user interactions that require such processes, requesting them to the Ingest Service.

The figure above shows the internal structure of the Ingest Service, which is split in two layers:
The Upper Layer implements the main logic of the Ingest Service using a modular design. It has a central node, the Core, which the logic of all possible workflows that can be followed by an upload, leaving data processing tasks to external modules. This means that the functionalities of the Ingest Service can be easily modified, replaced or extended by swapping these external modules with others, e.g., other Automatic Speech Recognition (ASR) and Machine Translation (MT) modules.
Actually, there exist 4 instances of the Ingest Service’s Core:
-
IS-Align: To manage text-to-speech alignment processes.
-
IS-Speech: To process video/audio objects.
-
IS-Text: To translate text objects.
-
IS-Web: To translate web pages.
External modules can be divided in two categories:
-
Base Modules: Modules that implement APIs for basic operations used by the Core.
-
Media Module: Module that offers several methods of media format conversion.
-
Text: Module to process text input data.
-
Format Adapters: Module that deals with the TLP’s internal data formats: <X10000, DFXP>> (for media subtitles) and DTLX (for text document translations).
-
Mailer Module: Module with routines used to send e-mail notifications regarding upload status updates.
-
URL Downloader: Module that allows for the download media files from a given URL address. It also offers the possibility of downloading obfuscated URLs such as YouTube or Vimeo using external plug-ins, called URL decoders.
-
-
Language Processing Modules: Modules that integrate text-to-speech alignment, transcription, translation and speech synthesis technologies into the Ingest Service. These modules have to be properly registered in the table
systemsof the Database.
Please note that propietary modules are not distributed with the public release of TLP, but module templates that you have to implement to integrate your own LP technologies. -
Align Modules: Automatic Text-to-Speech alignment modules, used to recover time alignments at the word level for input texts.
-
ASR Modules: Automatic Speech Recognition Modules, used to generate transcription subtitle files.
-
MT Modules: Machine Translation Modules, used to generate translated subtitle files, or to translate text documents.
-
TTS Modules: Text-To-Speech Modules, used to generate synthesized audiotracks in a specific language.
-
Text Retrieval Module: Extracts plain text information from the different file resources included in the MPF. It also downloads related text documents from the web. This text data can be used by ASR Modules to enhance transcription quality by adapting the underlying ASR System to the topic of the media file.
-
The Lower Layer satisfies all local installation dependencies related to data storage and job scheduling. It is split into two parallel sublayers:
-
Scheduler layer: Implements an API for launching and scheduling the transcription and translation processes, typically in a Grid Engine/Job Management System.
-
Storage layer: Implements an API that allows access to the data stored in the Database and in the TLP Server’s hard drive.
9.1. Uploads Workflow
In this section we explain the different steps an upload can follow from the moment it is ingested into the transLectures-UPV Platform until its processing finishes.
9.1.1. Video/Audio transcription and translation workflow
First we must distinguish between four types of operations:
-
New Media: This operation is requested when a newly-recorded, non-existing media is uploaded to TLP for the first time. In this operation, a new Media object is created in the Database.
-
Update Media: This operation is requested when updates are applied to an existing media. For instance, new text resources such as slides might be added to the Media Package File (MPF) to improve the automatic transcription and translations of the existing media, or to update the existing media file with a re-recording.
-
Delete Media: This operation is requested when a media is deleted from the remote repository.
-
Cancel Upload: This operation is requested to cancel an ongoing upload for whatever reason.
Depending on the type of operation and the input data, the steps an upload follows in the Ingest Service may vary. The figure below illustrates the standard Ingest Service workflow:

Media Package Files are uploaded to the transLectures-UPV Platform via the Web Service's /ingest interface and stored in the Database. The Ingest Service reads the uploads table of the database and starts processing the uploaded MPF. An upload will typically follow the following sequential steps, with some exceptions (some steps might be skipped depending on the input data):
-
Media Package Processing: The MPF is processed for the first time, performing several security, data integrity and data format checks, and, if all checks are correct, the upload status moves to the next processing step.
-
Transcription Generation: In this step, a transcription file in DFXP format is generated from the main media file (video, audio) using an Automatic Speech Recognition (ASR) Module.
This step is skipped in the following cases:
-
The Ingest Service does not feature a suitable ASR Module for the source language of the main media file.
-
Subtitles in the source language were provided in the MPF.
-
The client has explicitly not requested this step.
-
In update operations that do not involve re-transcribing the lecture.
-
In delete or cancel operations.
-
-
Translation(s) Generation: In this step, one or more translation files in DFXP format are generated from a transcription file (either automatically generated in the previous step, or provided in the MPF), using the appropriate Machine Translation Modules.
This step is skipped in the following cases:
-
The Ingest Service does not have suitable MT Modules for the source language of the main media file.
-
Subtitles in all requested translation languages offered by the Ingest Service are already provided in the MPF.
-
The client has explicitly not requested this step.
-
In update operations that do not involve re-translating the lecture.
-
In delete or cancel operations.
-
-
Text-To-Speech Track Generation: In this step one or more synthesized audiotrack files are generated from a translation file (either automatically generated in the previous step or provided in the MPF), using the appropriate Text-To-Speech Modules. This step is skipped in the following cases:
-
The Ingest Service does not have suitable TTS Modules for the target language of any translation files.
-
Audiotracks in all requested languages offered by the Ingest Service are already provided in the MPF.
-
The client has explicitly not requested this step.
-
In update operations that do not involve re-translating the lecture.
-
In delete or cancel operations.
-
-
Media Conversion: In this step, the main media file is converted into the media formats required by the TLP Player in order to maximize browser compatibility. This step is skipped in the following cases:
-
All required media files were attached in the MPF.
-
In update operations where the main media file has not changed.
-
In delete or cancel operations.
-
-
Store Data: This is the final step. For New Media and Update Media operations, the data contained in the MPF and the data automatically generated by the Ingest Service are stored in the Database. For Delete Media operations, all previously stored media files and data are deleted.
In every execution of the Ingest Service, the Core reviews which uploads are being processed, checking whether the related processes are:
-
Queued: Processes are queued when they are waiting to be executed. No action is performed.
-
Running: Processes are being executed. No action is performed.
-
Finished: All processes finished successfully. The Core changes the upload status to the next processing step.
-
Failed: Some processes failed. The Core changes the upload status to an error state.
Detailed information about the Ingest Service workflows and behaviour can be found in this Appendix.
9.1.2. Text/Document translation workflow
First we must distinguish between four types of operations:
-
New Document(s): This operation is requested when one or more new text documents are uploaded to TLP for the first time. In this operation, new Document objects are created in the Database.
-
Update Document(s): This operation is requested to update existing document files, either the source document or to regenerate automatic translations.
-
Delete Document(s): This operation is requested to delete existing document files.
-
Cancel Upload: This operation is requested to cancel an ongoing upload for whatever reason.
Depending on the type of operation and the input data, the steps an upload follows in the Ingest Service may vary. The figure below illustrates the standard Ingest Service workflow:

Media Package Files are uploaded to the transLectures-UPV Platform via the Web Service's /text/ingest interface and stored in the Database. The Ingest Service reads the uploads table of the database and starts processing the uploaded MPF. An upload will typically follow the following sequential steps, with some exceptions (some steps might be skipped depending on the input data):
-
Media Package Processing: The MPF is processed for the first time, performing several security, data integrity and data format checks, and, if all checks are correct, the upload status moves to the next processing step.
-
Translation(s) Generation: In this step, one or more translation files in are generated for every text document file using the appropriate Machine Translation Modules.
This step is skipped in the following cases:
-
The Ingest Service does not feature suitable MT Modules for the source language.
-
The client has explicitly not requested this step.
-
In update operations that do not involve re-translating the lecture.
-
In delete or cancel operations.
-
-
Store Data: This is the final step. For New Document(s) and Update Document(s) operations, the data contained in the MPF and the data automatically generated by the Ingest Service are stored in the Database. For Delete Document(s) operations, all previously stored document files and data are deleted.
In every execution of the Ingest Service, the Core reviews which uploads are being processed, checking whether the related processes are:
-
Queued: Processes are queued when they are waiting to be executed. No action is performed.
-
Running: Processes are being executed. No action is performed.
-
Finished: All processes finished successfully. The Core changes the upload status to the next processing step.
-
Failed: Some processes failed. The Core changes the upload status to an error state.
Detailed information about the Ingest Service workflows and behaviour can be found in this Appendix.
9.2. User Quota
Each API client account has an upload quota. This quota represents the remaining number of videos and media time for video objects, or the remaining number of document files, sentences and/or words for text objects, that the user can upload. Once a new media file or document or text contents are uploaded, the Ingest Service checks whether the client has enough quota to process that/these particular objects, updating accordingly the user’s quota after processing them. Automatic re-transcriptions and re-translations do not decrease the user’s quota.
|
|
The Ingest Service features a Test Mode that allows the client to perform integration tests without consuming quota, and obtaining fast responses. |
10. Postprocessor
The postprocessor is the module devoted to react to different type of user interactions with TLP. Its main tasks are the following:
-
Close/finish user edit sessions created on the Media Player or the Translation Editor in which no user activity nor web browser alive messages have been logged for a defined period of time.
-
Compute user interaction statistics as well as transcription and/or translation quality measures on closed edit sessions.
-
Issue callbacks to the Callback Service, right after an edit session ends, to inform API users about which caption files that have been updated.
-
Request automatic time alignments at the word level of supervised transcriptions to the Ingest Service.
-
Request the re-generation of translations and/or synthesized audiotracks to the Ingest Service, when applicable.
-
Look for untranslated texts from websites and send them to the Ingest Service to be translated.
-
Delete source and translated texts from websites no longer accessed for a defined period of time.
The postprocessor module is located under the misc/postprocessor folder.
11. Callback Service
The Callback Service is responsible of performing HTTP POST function calls to callback servers hosted by API clients. These callbacks can be issued by the Ingest Service to notify relevant updates about processing status of ongoing media uploads (started, finished, or failed), or by the Postprocessor module to notify manual post-editions of caption files. Callback functions are typically used to trigger automatic data processing workflows in the client side (e.g. publish objects on a media managament app, download updated captions for text indexing, etc.).
To receive these notifications through the Callback Service, API users must set
a callback server URL. Callback servers are queried by HTTP POST function calls
containing JSON data at its body. This JSON data contains key-value pairs with
relevant information. The Callback Service will automatically perform n retries
exponentially spaced in time, whenever the target callback server returns a
HTTP response code different than 200 OK.
The Callback Service can be configured to send JSON data as payload with JSON Web Tokens (JWT). JWTs allow API clients to verify the autenticity of both sender and JSON data. In this case, user’s API secret key is used as secret for the JWT signature.
Ingest Service callbacks
The Ingest Service will send notifications to the user-defined (default) callback server URL after relevant processing status changes of ongoing media uploads, such as a new upload has started its processing, has been completely processed, or has failed.
The user-defined callback server URL can be overriden on media ingestion by
setting up the "callback" dictionary in the Manifest JSON file.
Also, predefined parameters ("params") can be provided in the Manifest JSON
as a dictionary, so that the enclosed key-value pairs are to be also included
in the callback JSON data. A typical usage of these predefined parameters is to
provide an authentication token, as an alternative to JWT, to certificate the
autenticity of the sender. Please check Manifest JSON file for more
details.
POST data will include the following information, JSON-encoded:
{ "source" : "ingest-service" "external_id" : <str>, "language" : <str>, "upload_id" : <str>, "status" : <str>, "internal_status_code" : <int>, "error_code" : <int>, "info" : <str>, "user": <str>, "timestamp": <str> }
external_id:<str>
|
Media ID. |
language:<str>
|
Media language. |
upload_id:<str>
|
Upload ID. |
status:<str>
|
Simplified upload status. Possible values:
|
internal_status_code:<int>
|
Internal status code of the upload (check |
error_code:<int>
|
Generic error code that identifies the operation that failed within the process, if any. Otherwise null. |
info:<str>
|
Detailed information about the internal status code. |
user:<str>
|
API user name. |
timestamp:<str>
|
Status update timestamp. |
Please note that predefined parameters (params), when provided, will be included in the JSON data as well.
Example:
{ "source": "ingest-service", "external_id": "naked_trump-video7", "user": "joebiden", "language": "en", "upload_id": "up-ac83be70-a01c-4c18-8cc4-dc0b2676cbb0" "status": "RUNNING" "status_code": 2, "info": "Transcription in progress. It may take several hours for it to finish.", "timestamp": "2021-10-08 17:06:05.298861" }
Postprocessor callbacks
The Postprocessor module will send notifications to the user-defined callback server URL right after a user ends an editing session on the TLP Player, and, as a result, one or more caption files become modified. The callback service will perform as many HTTP POST calls as caption files involved.
POST data will include the following information, JSON-encoded:
{ "source" : "postprocessor", "external_id" : <str>, "language" : <str>, "supervision_status" : <int>, "supervision_ratio" : <float>, "info" : <str>, "user" : <str>, "timestamp" : <str> }
external_id:<str>
|
Media ID. |
language:<str>
|
Media language. |
supervision_status:<int>
|
Subtitle supervision status code. Defines the level of human supervision of the subtitles.
|
supervision_ratio:<float>
|
Percentage of supervised segments. |
info:<str>
|
Detailed information about the reason of the callback. |
user:<str>
|
API user name. |
timestamp:<str>
|
Status update timestamp. |
Example:
{ "source": "postprocessor", "external_id": "naked_trump-video7", "user": "joebiden", "supervision_status": 1, "supervision_ratio": 0.55, "language": "en", "info": "Captions updated by user post-editions", "timestamp": "2022-06-03 19:14:03.291811" }
12. Client tools
The transLectures-UPV Platform offers several libraries and command-line utilities in order to facilitate the client’s interaction with
the Web Service API, the TLP Media Player and the TLP Translation Editor. These tools
are located under the misc/client-tools folder.
-
Python →
libtlp.py(see Documentation) -
PHP →
libtlp.php(see Documentation)
-
Python-based (using
libtlp.py):-
ws-client.py: Script to call all Web Service interfaces. -
player-url-generator.py: Generates valid URLs to the TLP Media Player. -
tl-editor-url-generator.py: Generates valid URLs to the TLP Translation Editor. -
web-tl-editor-url-generator.py: Generates valid URLs to the TLP Web Translation Editor.
-
Appendices
Appendix A: Calling the TLP Media Player
The TLP Media Player must be called using different input parameters depending on which subtitles are being edited, the language of these subtitles and what kind of user is doing the editing. These parameters are sent as a Base64-encoded JSON string via HTTP GET or POST methods. A full request key is sent for the authentication of the API client on all Web Service calls. Optional configuration parameters can be sent to the Player as well.
|
|
API users should avoid sending their secret key on the Player input parameters, since these parameters are exposed to third-parties (i.e. external Player users) as they travel inside the URL to the Player. Please see Annex Generating a Request Key to learn how to produce valid full request keys in order to protect your private secret key. |
|
|
The transLectures-UPV Platform includes in its Client Tools Package the player-url-generator.py command-line script that
generates valid Player URLs for the given input parameters. The usage of the
--debug option might be very useful to check how these URLs are generated.
Furthermore, you will find libraries for different platforms that include
Player URL generation methods. |
Input parameters
{
"id" : <str> ,
"lang" : <str> ,
"author_id" : <str> ,
"author_conf" : <int> ,
"author_name" : <str> ,
"expire" : <int> ,
"api_user" : <str> ,
"request_key" : <str>
}
id:<str>
|
Media ID. |
lang:<str>
|
Language code of the subtitles being edited (i.e. en, es, ca). If this parameter is not defined, the Player will load the source language transcriptions (optional). |
author_id:<str>
|
ID of the user that will edit the subtitles. It is typically the internal user ID that the API client’s organisation assigns to the user. |
author_conf:<int>
|
Integer value (range 0-100) that indicates the confidence level that the API client’s organisation provide to the user. |
author_name:<str>
|
Full name of the user that will edit the subtitles (optional). |
expire:<int>
|
Expiration date of the URL in UNIX timestamp format. |
api_user:<str>
|
TLP username / API Client username (Please see Web Service user authentication). |
request_key:<str>
|
Request key (see Generating a Request Key). |
{ "id" : "id-001", "lang" : "en", "author_id" : "bobama", "author_conf" : 100, "author_name" : "Barack Obama", "expire" : 1400173491, "api_user" : "tluser", "request_key" : "5251982f3d00544e6e9a91962a2eec2f0b3df38c" }
Parameters are sent as a Base64-encoded JSON string. The JSON string for the above example would be as follows:
{"id" : "id-001", "lang" : "en", "author_id" : "bobama", "author_conf" : 100, "author_name" : "Barack Obama", "expire" : 1400173491, "api_user" : "tluser", "request_key" : "5251982f3d00544e6e9a91962a2eec2f0b3df38c"}
Base64 encode of the above JSON string:
eyJpZCIgOiAiaWQtMDAxIiwgImxhbmciIDogImVuIiwgImF1dGhvcl9pZCIgOiAiYm9iYW1hIiwgImF1dGhvcl9jb25mIiA6IDEwMCwgImF1dGhvcl9uYW1lIiA6ICJCYXJhY2sgT2JhbWEiLCAiZXhwaXJlIiA6IDE0MDAxNzM0OTEsICJhcGlfdXNlciIgOiAidGx1c2VyIiwgInJlcXVlc3Rfa2V5IiA6ICI1MjUxOTgyZjNkMDA1NDRlNmU5YTkxOTYyYTJlZWMyZjBiM2RmMzhjIn0=Configuration parameters
The TLP Media Player can receive optional configuration parameters from the URL (GET parameter params). These are passed as a JSON object, codified as a Base64 string. Supported parameters are:
autosave:<int=0>
|
Number of seconds between automatically saving changes (0 to disable autosave). |
mode:<str={'editor','transcriptor'}>
|
Editing mode (default: editor). |
appLayout:<str={'side','updown','full','viewer'}>
|
Arrangement of elements in the screen (default: side). |
mediaPlayerWidth:<str='50%'>
|
Video default width. |
controlsHiddenTimeout:<int=500>
|
Milliseconds for hiding video controls (0 to disable). |
fontSize:<int=14>
|
Font size. |
optCps:<int=15>
|
Optimum number of characters per second. |
maxCps:<int=17>
|
Maximum number of characters per second. |
maxCharsPerLine:<int=36>
|
Maximum characters per line. |
minSegDuration:<float=1.0>
|
Minimum segment duration (in seconds). |
maxSegDuration:<float=6.0>
|
Maximum segment duration (in seconds). |
invertMouseWheel:<bool=false>
|
Invert mouse wheel direction on waveform bar. |
hideSegmenterButtons:<bool=false>
|
Hide split and remove buttons from segmenter bar segments. |
{ "mode" : "editor", "layout" : "updown" }
Parameters are sent as a Base64-encoded JSON string. The JSON string for the above example would be as follows:
{"mode" : "editor", "layout" : "updown"}
Base64 encode of the above JSON string:
eyJtb2RlIiA6ICJlZGl0b3IiLCAibGF5b3V0IiA6ICJ1cGRvd24ifQ==HTTP call
The requested Base64 JSON string is received by the Player via HTTP GET or POST methods using the following parameters:
-
request → Base64 JSON string with request parameters
-
t → Media start time in seconds (optional)
-
params → Base64 JSON string with optional configuration parameters (optional)
http://my-tlp-server.com/player?request=eyJpZCIgOiAiaWQtMDAxIiwgImxhbmciIDogImVuIiwgImF1dGhvciIgOiAiYm9iYW1hIiwgImF1dGhvcl9uYW1lIiA6ICJCYXJhY2sgT2JhbWEiLA0KImF1dGhvcl9jb25mIiA6IDEwMCwgImludGVybmFsdXNlciIgOiAwLCAiZXhwaXJlIiA6IDE0MDAxNzM0OTEsICJhcGlfdXNlciIgOiAidGx1c2VyIiwgDQoicmVxdWVzdF9rZXkiIDogIjUyNTE5ODJmM2QwMDU0NGU2ZTlhOTE5NjJhMmVlYzJmMGIzZGYzOGMifQ==¶ms=eyJtb2RlIiA6ICJlZGl0b3IiLCAibGF5b3V0IiA6ICJ1cGRvd24ifQ==Appendix B: Calling the TLP Translation Editor
The TLP Translation Editor must be called using different input parameters depending on which document is being edited, the language of the translation and what kind of user is doing the editing. These parameters are sent as a Base64-encoded JSON string via HTTP GET or POST methods. A full request key is sent for the authentication of the API client on all Web Service calls.
|
|
API users should avoid sending their secret key on the input parameters, since these parameters are exposed to third-parties (i.e. external users) as they travel inside the URL to the Editor. Please see Annex Generating a Request Key to learn how to produce valid full request keys in order to protect your private secret key. |
Input parameters
{
"id" : <str> ,
"lang" : <str> ,
"author_id" : <str> ,
"author_conf" : <int> ,
"author_name" : <str> ,
"expire" : <int> ,
"api_user" : <str> ,
"request_key" : <str>
}
id:<str>
|
Media ID. |
lang:<str>
|
Language code of the translation being edited (i.e. en, es, ca). |
author_id:<str>
|
ID of the user that will edit the translation. It is typically the internal user ID that the API client’s organisation assigns to the user. |
author_conf:<int>
|
Integer value (range 0-100) that indicates the confidence level that the API client’s organisation provide to the user. |
author_name:<str>
|
Full name of the user that will edit the translation (optional). |
expire:<int>
|
Expiration date of the URL in UNIX timestamp format. |
api_user:<str>
|
TLP username / API Client username (Please see Web Service user authentication). |
request_key:<str>
|
Request key (see Generating a Request Key). |
{ "id" : "id-001", "lang" : "en", "author_id" : "bobama", "author_conf" : 100, "author_name" : "Barack Obama", "expire" : 1400173491, "api_user" : "tluser", "request_key" : "5251982f3d00544e6e9a91962a2eec2f0b3df38c" }
Parameters are sent as a Base64-encoded JSON string. The JSON string for the above example would be as follows:
{"id" : "id-001", "lang" : "en", "author_id" : "bobama", "author_conf" : 100, "author_name" : "Barack Obama", "expire" : 1400173491, "api_user" : "tluser", "request_key" : "5251982f3d00544e6e9a91962a2eec2f0b3df38c"}
Base64 encode of the above JSON string:
eyJpZCIgOiAiaWQtMDAxIiwgImxhbmciIDogImVuIiwgImF1dGhvcl9pZCIgOiAiYm9iYW1hIiwgImF1dGhvcl9jb25mIiA6IDEwMCwgImF1dGhvcl9uYW1lIiA6ICJCYXJhY2sgT2JhbWEiLCAiZXhwaXJlIiA6IDE0MDAxNzM0OTEsICJhcGlfdXNlciIgOiAidGx1c2VyIiwgInJlcXVlc3Rfa2V5IiA6ICI1MjUxOTgyZjNkMDA1NDRlNmU5YTkxOTYyYTJlZWMyZjBiM2RmMzhjIn0=HTTP call
The requested Base64 JSON string is received by the Editor via HTTP GET or POST methods using the following parameters:
-
request → Base64 JSON string
http://my-tlp-server.com/docedit?request=eyJpZCIgOiAiaWQtMDAxIiwgImxhbmciIDogImVuIiwgImF1dGhvcl9pZCIgOiAiYm9iYW1hIiwgImF1dGhvcl9jb25mIiA6IDEwMCwgImF1dGhvcl9uYW1lIiA6ICJCYXJhY2sgT2JhbWEiLCAiZXhwaXJlIiA6IDE0MDAxNzM0OTEsICJhcGlfdXNlciIgOiAidGx1c2VyIiwgInJlcXVlc3Rfa2V5IiA6ICI1MjUxOTgyZjNkMDA1NDRlNmU5YTkxOTYyYTJlZWMyZjBiM2RmMzhjIn0=Appendix C: Calling the TLP Web Translation Editor
The TLP Translation Editor must be called using different input parameters depending on which document is being edited, the language of the translation and what kind of user is doing the editing. These parameters are sent as a Base64-encoded JSON string via HTTP GET or POST methods. A full request key is sent for the authentication of the API client on all Web Service calls.
|
|
API users should avoid sending their secret key on the input parameters, since these parameters are exposed to third-parties (i.e. external users) as they travel inside the URL to the Editor. Please see Annex Generating a Request Key to learn how to produce valid full request keys in order to protect your private secret key. |
Input parameters
{
"id" : <str> ,
"expire" : <int> ,
"api_user" : <str> ,
"request_key" : <str> ,
"lang" : <str>
}
id:<str>
|
Website key string. |
expire:<int>
|
Expiration date of the URL in UNIX timestamp format. |
api_user:<str>
|
TLP username / API Client username (Please see Web Service user authentication). |
request_key:<str>
|
Request key (see Generating a Request Key). |
lang:<str>
|
Language code of the translation being edited (i.e. en, es, ca). |
{ "id" : "b16fc9bfc043752047d7b932fedc861e", "lang" : "es", "expire" : 1400173491, "api_user" : "tluser", "request_key" : "5251982f3d00544e6e9a91962a2eec2f0b3df38c" }
Parameters are sent as a Base64-encoded JSON string. The JSON string for the above example would be as follows:
{"id" : "b16fc9bfc043752047d7b932fedc861e", "lang" : "es", "expire" : 1400173491, "api_user" : "tluser", "request_key" : "5251982f3d00544e6e9a91962a2eec2f0b3df38c"}
Base64 encode of the above JSON string:
eyJpZCIgOiAiYjE2ZmM5YmZjMDQzNzUyMDQ3ZDdiOTMyZmVkYzg2MWUiLCAibGFuZyIgOiAiZXMiLCAiZXhwaXJlIiA6IDE0MDAxNzM0OTEsICJhcGlfdXNlciIgOiAidGx1c2VyIiwgInJlcXVlc3Rfa2V5IiA6ICI1MjUxOTgyZjNkMDA1NDRlNmU5YTkxOTYyYTJlZWMyZjBiM2RmMzhjIn0=HTTP call
The requested Base64 JSON string is received by the Editor via HTTP GET or POST methods using the following parameters:
-
request → Base64 JSON string
http://my-tlp-server.com/webtledit?request=eyJpZCIgOiAiaWQtMDAxIiwgImxhbmciIDogImVuIiwgImF1dGhvcl9pZCIgOiAiYm9iYW1hIiwgImF1dGhvcl9jb25mIiA6IDEwMCwgImF1dGhvcl9uYW1lIiA6ICJCYXJhY2sgT2JhbWEiLCAiZXhwaXJlIiA6IDE0MDAxNzM0OTEsICJhcGlfdXNlciIgOiAidGx1c2VyIiwgInJlcXVlc3Rfa2V5IiA6ICI1MjUxOTgyZjNkMDA1NDRlNmU5YTkxOTYyYTJlZWMyZjBiM2RmMzhjIn0=Appendix D: Web Service API: Technical Preface
|
|
The transLectures-UPV Platform includes in its Client Tools Package several libraries for different platforms that implement
all the interfaces described below. Also, you will find in that package the
ws-client.py command-line tool ready to be used for making all
these API calls. |
Please read carefully the following considerations before interacting with this API. These considerations are valid for almost all API interfaces except for /web/getjs, /web/translate and /web/amend.
Allowed HTTP methods
The interfaces featured by the Web Service can be called using either GET or POST methods.
-
GET Method:
-
Using multiple GET parameters. Example:
GET Parameters:
parameter1=value1 parameter2=value2URL:
http://my-tlp-server.com/api/action?parameter1=value1¶meter2=value2 -
Using a single Base64-encoded JSON dict
dataGET parameter. Example:Parameters encoded into a JSON Dict:
{"parameter1":"value1", "parameter2": "value2"}Base64-encoded JSON dict:
eyJwYXJhbWV0ZXIxIjoidmFsdWUxIiwgInBhcmFtZXRlcjIiOiAidmFsdWUyIn0URL:
http://my-tlp-server.com/api/action?data=eyJwYXJhbWV0ZXIxIjoidmFsdWUxIiwgInBhcmFtZXRlcjIiOiAidmFsdWUyIn0
-
-
POST Method:
-
All interfaces except /ingest/new and ingest/update:
-
Content-Type: application/json
-
Query parameters: must be sent as a JSON dictionary in the body of the request.
-
-
-
/ingest/new and ingest/update interfaces. Two possibilities:
-
Content-Type: application/json as above, or
-
Content-Type: multipart/form-data, if a media/document package have to be uploaded too.
-
Query parameters: must be sent as a JSON dictionary stored in a field called
json:-
Content-Disposition: form-data; name="json"; Content-Type: application/json
-
-
Media Package or Document Package: must be sent as a zip file in a field called
pkg:-
Content-Disposition: form-data; name="pkg"; Content-Type: application/zip
-
-
-
-
|
|
The Web Service will return an HTTP 400 Bad Request error code whenever required arguments are missing or are provided under an incorrect format. |
|
|
The ws-client.py command-line tool implements (via the
libtlp python library) all possible ways to send query
parameters to the API described above (see the options --use-get-query and
--use-data-param). If you plan to implement your own API client, the
--debug option of this script might be very useful for you to check how
parameters and HTTP calls must be generated. |
API Client Authentication
-
API clients have to send in every call to the Web Service the following parameters:
-
user→ API Client username / TLP username, -
auth_token→ The authentication token for user authentication.
-
-
And additionally, if
auth_tokenis a request_key:-
expire→ Expiration date UNIX timestamp for the request (seconds since 01-01-1970 in UTC to the expiration date).
-
-
To learn how to generate a valid request key, please refer to the Generating a Request Key Annex.
-
The request key authentication method is valid for all interfaces, except /ingest, /uploadslist, /status, /systems and /revisions.
-
The Web Service will return the following HTTP error codes:
-
401 Unauthorized, if:
-
The API user does not exist,
-
the authentication token is invalid,
-
the API user does not have permissions to get information about the provided object ID.
-
-
419 Authentication Timeout, if:
-
the authentication token has expired (only for Request Key).
-
-
Appendix E: Web Service API: /speech API specifications
Please note that all the following interfaces will share a common prefix: /speech.
|
/ingest
|
Upload media (audio/video) files and any attachments and metadata to the TLP Server for automatic multilingual subtitling and speech synthesis. |
|
/uploadslist
|
Get a list of all the user’s uploads. |
|
/status
|
Check the current status of a specific upload ID. |
|
/systems
|
Get a list of all available Speech Recognition, Machine Translation, Subtitle post-processing, and Text-To-Speech Systems that can be applied to transcribe, translate, and synthesize a media file. |
|
/list
|
Get a list of all existing audio and videos in the Database. |
|
/metadata
|
Get metadata and media file locations for a given media ID. |
|
/langs
|
Get a list of all subtitle and audiotrack languages available for a given media ID. |
|
/get
|
Download the current subtitle file for a given media ID and language. |
|
/getmod
|
Get subtitle modifications in JSON format of a given media and session ID. |
|
/audiotrack
|
Download an audiotrack file for a given media ID and language. |
|
/active_sessions
|
Returns information about active edition sessions involving a particular media ID. |
|
/start_session
|
Starts an edition session to send and commit modifications of a subtitles file. |
|
/session_status
|
Returns the current status of the given session ID. |
|
/mod
|
Send and commit subtitle corrections under an edit session. |
|
/align
|
Request automatic alignments of long manual speech transcripts with the corresponding audio. |
|
/end_session
|
Ends an open edition session, and depending on the confidence of the user, editions are directly stored in the corresponding subtitles files or left for revision. |
|
/lock
|
Allow/disallow regular users to send subtitles modifications for an specific Media ID. |
|
/edit_history
|
Returns a list of all edit sessions that involved an specific media ID. |
|
/revisions
|
Returns a list of all edit sessions for all API user’s media files that are pending to be revised. |
|
/mark_revised
|
Mark/unmark as revised an specific edit session ID, typically from another Session ID on the TLP Player. |
|
/accept
|
Accept modifications of one or more pending edit sessions without having to revise them. Modifications are commited into the corresponding subtitles files. |
|
/reject
|
Reject modifications of one or more pending edit sessions without having to revise them. |
/speech/ingest
This interface allows the client to upload media files to the platform so they can be automatically transcribed and translated into several languages by the Ingest Service. The uploaded data (media, slides, documents, etc.) are bundled into a non-compressed ZIP file called Media Package (MPF). The Web Service stores the Media Packages in the server and returns an Upload ID, which can be used afterwards to check the upload progress via the /status interface. In addition, the Ingest Service can issue callbacks to notify relevant upload status updates; please check Callback Service.
|
|
If you are developing your own API client, it is recommended to enable the Test Mode of the Ingest Service when performing call tests to this interface. Please refer to the Manifest JSON File Specification. |
The /ingest interface is split into four sub-interfaces, every one devoted to implement the four operation types supported by the Ingest Service:
Every sub-interface has different input specifications, please refer to each sub-section. Particularly, the /new and /update operations require as input a base64-encoded Manifest JSON string (please see Manifest JSON sub-section). In case any media files have to be uploaded to the TLP Server, those files have to be declared in the Manifest JSON string, and attached to the HTTP query as a Media Package file (please see Media Package sub-section). Finally, all sub-interfaces share the same output specifications, please see the Output sub-section.
Manifest JSON
The Manifest JSON is a JSON string that provides several metadata required by the /new and /update operations. For example, on new operations it must describe media attributes such as ID, title or language. Also, it is used to tell the Ingest Service that one or more media files such as a video file or a slides file have been uploaded, bundled into a Media Package file.
Manifest file JSON Specification
{
"media" : {
"filename" : <str> ,
"fileformat" : <str> ,
"md5" : <str> ,
"slides" : <bool> ,
"url" : <str>
} ,
"attachments" : [
{
"filename" : <str> ,
"fileformat" : <str> ,
"md5" : <str> ,
"type_code" : <str> ,
"language" : <str> ,
"human" : <bool>
},
...
] ,
"metadata" : {
"external_id" : <str> ,
"language" : <str> ,
"title" : <str> ,
"topic" : <str> ,
"keywords" : <str> ,
"date" : <str> ,
"speakers" : [
{
"speaker_id" : <int> ,
"speaker_name" : <str> ,
"speaker_gender" : <str> ,
"speaker_email" : <str>
} ,
...
]
},
"requested_langs": <dict> ,
"generate" : <bool> ,
"re-generate": [ <str>, ...] ,
"force": <int> ,
"test_mode" : <bool>,
"email": [ <str>, ...],
"callback":{
"url": <str>,
"params": <dict>
}
}-
media:
<dict>→ Main media file to be transcribed and/or translated.<dict>keys:-
filename:
<str>→ File name of the main media file. -
fileformat:
<str>→ Format of the main media file (see Allowed attachments). -
md5:
<str>→ MD5 checksum of the main media file. -
slides:
<bool>→ Use media file also as a video slides file (optional, defaultfalse). -
url:
<str>→ URL to the main media file. If a url field is given, fields filename, fileformat and md5 are ignored.
-
-
metadata:
<dict>→ Media metadata.<dict>keys:-
external_id:
<str>→ Media ID (typically an internal ID in the client’s media repository database) used to identify the video in further queries to the Web Service. -
title:
<str>→ Title of the media. -
language:
<str>→ Media language code in ISO 639-1 format (e.g. "en", "es"). -
speakers:
<list:dict>→ Information about the speaker(s) of the media.<dict>keys:-
speaker_id:
<int>→ Speaker ID (client). -
speaker_name:
<str>→ Full name of the speaker. -
speaker_email:
<str>→ E-mail of the speaker (optional). -
speaker_gender:
<str>→ Gender of the speaker (optional).-
M→ Male. -
F→ Female.
-
-
-
topic:
<str>→ Topic of the media (optional). -
keywords:
<str>→ Media keywords (optional). -
date:
<str>→ Publication date of the media (optional).
-
-
attachments:
<list:dict>→ Additional files that have been attached to the media package, such as slides, related documents or subtitles.<dict>keys:-
filename:
<str>→ File name of the attachment. -
fileformat:
<str>→ Format of the attachment (see Allowed attachments). -
md5:
<str>→ MD5 checksum of the attachment. -
type_code:
<int>→ Attachment type code (see Allowed attachments).-
0→ Media file. -
1→ Slides file. -
2→ Related text document file. -
3→ Video Snapshot/Thumbnail file. -
4→ Subtitles file. -
5→ Audiotrack file. -
6→ PCM waveform file. -
7→ Non-timed transcript text file.
-
-
language:
<str>→ Language of the attachment, in case it is a subtitles file, in ISO 639-1 format (e.g. "en", "es") (optional, but mandatory if type_code=4). -
human:
<bool>→ If the attachment is a subtitles file, determine if provided subtitles have been generated by humans (optional, defaulttrue).
-
-
requested_langs:
<dict>→ Explicit request of subtitles and audiotrack languages, along with some advanced options. Please see Requesting subtitle languages (optional). -
generate:
<bool>→ Enable/disable transcription and translation technologies (optional, defaulttrue). -
re-generate:
<list:str>→ On update operation: request a regeneration of translations and/or synthesized audiotracks. Must be a list of keywords (optional). Allowed Keywords:-
tx→ Request regeneration of the media transcription. -
tl→ Request regeneration of media translations. -
tts→ Request regeneration of synthesized audiotracks.
-
-
force:
<bool>→ On update operation: Force regeneration of automatic subtitles even if there exist human-supervised subtitles (optional, defaultfalse). -
test_mode:
<bool>→ Enable/Disable the Test Mode of the Ingest Service. When enabled, the uploaded media will be available inmediately with an empty subtitles file. This feature is very useful when executing integration tests with the /ingest interface (optional, defaultfalse). -
email:
<list:str>→ List of emails to send notifications about the status of the upload (optional). -
callback:
<dict>→ Override default user-defined callback server URL (if any), to which notify upload status updates (optional). See Callback Service for more information.<dict>keys:-
url:
<str>→ URL of the HTTP callback server (e.g. https://my-server.com/my-callback) -
params:
<dict>→ Predefined parameters to be sent back in the callback (e.g.{"auth_token":"dO(.$aKL8"})
-
Requesting Subtitle Languages
The requested_langs option, as stated before, is used to request additional subtitle languages, specifying advanced transcription, translation or text-to-speech options. requested_langs is a JSON dictonary in which keys are ISO 639-1 language codes (e.g. "en", "es"), and values are dictionaries in which keys are the objects or outputs requested to be generated for that particular language, and values are dictionaries with advanced options. Those keys (objects) might be:
-
sub:
<dict>→ Generate subtitles for that specific language. -
tts:
<dict>→ Generate text-to-speech audiotracks for that specific language.
|
|
sub and tts values can be empty dictionaries ({}) or null values, if no
advanced options are specified. |
"requested_langs": { "es": { "sub": {} }, "en": { "tts": {}, "sub": {} } }
The example above means: "Generate Spanish and English subtitles and a English TTS audiotrack, using default options in all cases".
Advanced options:
-
sub options:
-
sid:
<int>→ Specify which System will be applied to generate the transcription, translation, or audiotrack file. If not specified, the default system is used. -
lma:
<bool>→ Only for transcriptions (ASR): Enable or disable Language Model Adaptation. By default it is enabled. -
postproc:
<bool>→ For transcriptions and translations (ASR/MT): Enable/Disable subtitle postprocessing using a particular subtitle-postproc module (i.e. converts raw ASR output to true-cased subtitles with punctuation, digits, etc.). If no postproc_sid option is provided, then a default subtitle-postproc module for the corresponding subtitle language (if available) will be run. By default, this option is set toTrue. -
postproc_sid:
<int>→ Specify the subtitle-postproc module that will be used to postprocess ASR or MT output. -
tlpath:
<list>→ Only for translations (MT): Explicitly declare a Translation Path. This is useful to generate translations to a language which is not featured directly from the spoken language, using intermediate translation languages. It is declared as an ordered list of dictionaries, where each dictionary specifies the target language code l of the step, and optionally the System ID sid to apply.The example below shows how to request Catalan (
ca) subtitles from the spoken language (XX) using English (en) and Spanish (es) as intermediate languages, thus defining the following translation path:XX->En->Es->Ca. The intermediateEn->Estranslation is generated using System ID 3."requested_langs": { "ca": { "sub": { "tlpath": [ { "l":"en" }, { "l":"es", "sid":3}, { "l":"ca"} ] } } }
If this option is not specified, the Ingest Service will assume that a direct translation from the spoken language is requested.
-
-
tts options:
-
sid:
<int>→ Specify which System ID will be applied to generate the synthesized audiotrack. If not specified, the default system is used.
-
The following example of the requested_langs option
requests Estonian (et) subtitles disabling the Language Model Adaptation
feature and making use of the System ID 22, as well as English (en) subtitles with
default options and a synthesized English audiotrack using System ID 54.
"requested_langs": { "et": { "sub": { "lma":false, "sid":22 } } "en": { "sub": { } "tts": { "sid":54 } } }
Allowed attachments
Below follows a table in which are listed the attachents and file formats that are typically allowed to be uploaded to a standard Ingest Service.
| Type Code ID | Type Code Name | Allowed File Format List |
|---|---|---|
0 |
Media (video) |
mp4, m4v, ogv, wmv, avi, mpg, flv. |
0 |
Media (audio) |
wav, mp3, oga, flac, aac. |
1 |
Slides (text) |
txt, ppt, pptx, doc, docx, pdf. |
1 |
Slides (video) |
mp4, m4v, ogv, wmv, avi, mpg, flv. |
2 |
Documents |
txt, doc, docx, ppt, pptx, pdf. |
3 |
Video Thumbnail |
jpg. |
4 |
Subtitles |
dfxp, srt, trs. |
5 |
Audiotracks |
wav, mp3, oga, flac, aac. |
6 |
PCM waveform |
pcm. |
7 |
Non-timed transcript (text) |
txt. |
Media Package
A Media Package File is an uncompressed ZIP file that contains several media files and attachments declared in the Manifest JSON data sent to the /ingest/new or /ingest/update interfaces. All files must be placed in the root on the ZIP package (not inside folders or sub-folders).
Output
All four sub-interfaces share a common output specification, described as follows:
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"id" : <str> ,
"hash" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
id:<str>
|
Upload ID, which can be used afterwards to check the progress of the upload via the /status interface. |
hash:<str>
|
Internal media hash ID. |
Output Examples
{ "rcode" : 0, "rcode_description" : "Ingestion complete", "id" : "UPLOAD-ID-1234" "hash" : "433e11c295c51b94a074a" }
/speech/ingest/new
New media operation.
Input
In this operation only the POST method is allowed (Content-Type: multipart/form-data). Input data is divided in two fields:
-
json: Query parameters encoded in a JSON string (Content-Type: application/json)Parameter name Type Required Description Example manifest
json
Yes
Manifest JSON. See particular specifications for this operation.
[See this example]user
str
Yes
TLP Username / API Username.
tluserauth_token
str
Yes
Authentication token for the provided
user.edbab44c3a3f1ca8db4de8277a3b -
pkg(optional): A Media Package zip file (Content-Type: application/zip).
Manifest JSON data
Below is described how to properly set up a Manifest JSON string for New media operations.
Required inputs:
-
A media file to be transcribed and/or translated in the media section.
-
Required metadata keys:
-
external_id → Media ID in the remote (client) repository.
-
title → Title of the Media. It must be as descriptive as possible, since it might be used to search and download from the Internet related documents in order to adapt the ASR system to the topic of the video and enhance the quality of the automatic subtitles.
-
language → Spoken language of the media file, in ISO 639-1 format (e.g. "en", "es").
-
speakers → Speaker(s) info.
-
Behavior changes with optional inputs
-
requested_langs option:
-
Not provided: By default the media only will be transcribed, if possible and if needed (depending on the provided attachments). No translation nor TTS processes are launched.
-
Provided: Actions that can be inferred from this option will be executed, unless the expected outputs are already provided in the attachments section.
-
-
attachments section:
-
Perform a speech-to-text alignment instead of an ASR to generate a transcription file:
-
Non-timed transcript file: The ingest service will run a speech-to-text alignment module, instead of an ASR module, to generate a timed transcription file, using the provided non-timed transcript file as input.
-
-
Topic/Domain Adaptation for transcription depending on provided attachments: If Topic/Domain Adaptation is enabled for the ASR System that generates the transcription file, this ASR system will be adapted to the domain/topic of the media using different textual resources:
-
No text attachments provided: By default, adaptation will be carried out using external resources automatically downloaded from the Internet based on a web search using the title of the media. To disable topic adaptation, set
"lma":falseatrequested_langsoption. -
A slides file: The adaptation will be carried out using the text extracted from the slides file.
-
Related documents: The adaptation will be carried out using the text extracted from the attached documents.
-
A slides file + Related documents: The adaptation will be carried out using both the text extracted from the slides file and the text extracted from the attached documents.
-
-
Providing expected outputs:
-
Subtitles file (spoken language): Media won’t be transcribed. Subtitles will be translated and afterwards synthesized if explicitly requested in the requested_langs option.
-
Subtitles files (other languages): Media will be firstly transcribed, and then translated into other destination languages, except for the provided subtitles language, if explicitly requested in the requested_langs option. Synthesized audiotracks will be also generated if explicitly requested.
-
Subtitles files (spoken language + other languages): The media will be translated into the remaining available destination languages, if any and if explicitly requested in the requested_langs option. Synthesized audiotracks will be generated if explicitly requested.
-
Audiotrack files: Synthesized audiotracks for the languages of the attached audiotracks won’t be generated even if they were explicitly requested.
-
-
Call examples
-
JSON string:
{ "user": "tluser", "auth_token": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "media": { "url": "http://my-media-server.com/path/to/my/video.mp4" }, "metadata": { "external_id": "9abc7230fe36a18b885c", "language": "en", "title": "To know something or not to know nothing: A brief essay about knowledge.", "speakers": [ { "speaker_name": "Kit Harington", "speaker_id": "kit1234" } ] } } }
-
HTTP Call to /ingest/new (note that a Media Package file is not required in this case).
http://my-tlp-server.com/api/speech/ingest/new + POST data (JSON string goes in the "json" field)
-
JSON string:
{ "user": "tluser", "auth_token": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "media": { "fileformat": "mp4", "md5": "05b59346bc3fe5d3eac7a0dcd0022fb6", "filename": "main_media.mp4" }, "attachments": [ { "filename":"awesome_slides_in_video_format.wmv", "fileformat":"wmv", "type_code":1, "md5":"c8722d0e8e27d4b5caaa7122a14676e3" } ], "requested_langs": { "es": { "sub": {}, "tts": {} }, "en": { "sub": {} } }, "metadata": { "external_id": "9abc7230fe36a18b885c", "language": "en", "title": "To know something or not to know nothing: A brief essay about knowledge.", "speakers": [ { "speaker_email": "kit@got.com", "speaker_name": "Kit Harington", "speaker_gender": "M", "speaker_id": "kit1234" } ] } } }
-
HTTP Call to /ingest/new:
http://my-tlp-server.com/api/speech/ingest/new + POST data (JSON string goes in the "json" field, Media Package file in the "pkg" field)
/speech/ingest/update
Update media operation.
Input
In this operation only the POST method is allowed (Content-Type: multipart/form-data). Input data is divided in two fields:
-
json: Query parameters encoded in a JSON string (Content-Type: application/json)Parameter name Type Required Description Example manifest
json
Yes
Manifest JSON. See particular specifications for this operation.
[See this example]user
str
Yes
TLP Username / API Username.
tluserauth_token
str
Yes
Authentication token for the provided
user.edbab44c3a3f1ca8db4de8277a3b -
pkg(optional): A Media Package zip file (Content-Type: application/zip).
Manifest JSON data
Below is described how to properly set up a Manifest JSON string for Update media operations.
Required inputs:
-
Required metadata keys:
-
external_id → Media ID in the remote (client) repository.
-
Behavior changes with optional inputs
-
media section:
-
Not Provided: the Ingest Service will re-generate transcriptions, translations and/or audiotracks depending on the provided attachments and other options (see below).
-
Provided: the uploaded media is assumed to be a re-recording of the existing media; therefore a new transcription file needs to be generated. The Ingest Service will behave as described in the New Media operation. The only difference between both cases is that the video ID is kept. Old media file and subtitles are backed up.
-
-
requested_langs option:
-
Not provided: By default the media only will be transcribed, if possible and if needed (depending on the provided attachments). No translation nor TTS processes are launched.
-
Provided: Actions that can be inferred from this option will be executed, unless the expected outputs are already provided in the attachments section. Actions that involve the re-generation of subtitles that have already been edited or supervised by users won’t be executed, unless the force option is set to
true.
-
-
re-generate option:
-
tx: Transcription file will be automatically regenerated if not supervised before by a user, unless the force option is set totrue. -
tl: Translation files will be automatically regenerated if not supervised before by a user, unless the force option is set totrue. -
tts: Synthesized audiotracks will be automatically regenerated.
-
-
attachments section:
-
Perform a speech-to-text alignment instead of an ASR to generate a transcription file:
-
Non-timed transcript file: The ingest service will run a speech-to-text alignment module, instead of an ASR module, to generate a timed transcription file, using the provided non-timed transcript file as input.
-
-
Topic/Domain Adaptation for transcription depending on provided attachments: If Topic/Domain Adaptation is enabled for the ASR System that generates the transcription file, this ASR system will be adapted to the domain/topic of the media using different textual resources:
-
No text attachments provided: By default, adaptation will be carried out using external resources automatically downloaded from the Internet based on a web search using the title of the media. To disable topic adaptation, set
"lma":falseatrequested_langsoption. -
A slides file: The adaptation will be carried out using the text extracted from the slides file.
-
Related documents: The adaptation will be carried out using the text extracted from the attached documents.
-
A slides file + Related documents: The adaptation will be carried out using both the text extracted from the slides file and the text extracted from the attached documents.
-
-
Providing outputs:
-
Subtitles file (spoken language): Current transcription file will be overwritten by the supplied one. Subtitles will be translated and afterwards synthesized if explicitly requested in the requested_langs option, or the re-generate option contains the token tl for translation and tts for synthesis.
-
Subtitles files (other languages): Current translation files (if existing) will be overwritten by the supplied ones. Other subtitles languages will be generated if explicitly requested in the requested_langs option, or the re-generate option contains the token tl. Synthesized audiotracks will be also generated if explicitly requested either with the requested_langs option or the re-generate option.
-
Audiotrack files: Synthesized audiotracks for the languages of the attached audiotracks won’t be generated even if they were explicitly requested.
-
-
Call examples
-
JSON string:
{ "user": "tluser", "key": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "metadata": { "external_id":"9abc7230fe36a18b885c" }, "re-generate": [ "tl", "tts" ] } }
-
HTTP Call to /ingest/update (note that no Media Package file is required).
http://my-tlp-server.com/api/speech/ingest/update + POST data (JSON string goes in the "json" field)
-
JSON string:
{ "user": "tluser", "auth_token": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "media": { "filename": "main_media_NEW_VERSION.mp4" , "fileformat": "mp4" , "md5": "a86fae8e7af6fd6786efa876fa0e4212" }, "metadata": { "external_id": "9abc7230fe36a18b885c", "language": "en", "title": "To know something or not to know nothing: A brief essay about knowledge. (NEW VERSION)", "speakers": [ { "speaker_email": "kit@got.com", "speaker_name": "Kit Harington", "speaker_gender": "M", "speaker_id": "kit1234" } ] } } }
-
HTTP Call to /ingest/update:
http://my-tlp-server.com/api/speech/ingest/update + POST data (JSON string goes in the "json" field, Media Package file in the "pkg" field)
/speech/ingest/delete
Delete media operation.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
mode |
str |
No |
Delete mode. * * |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/ingest/delete?id=MEDIA-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3b/speech/ingest/cancel
Cancel upload operation.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Upload ID, returned by the /ingest interface. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/ingest/cancel?id=UPLOAD-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3b/speech/uploadslist
Returns a list of all user’s uploads.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
object_id |
str |
No |
Get list of uploads involving the provided object ID (could be an Upload ID or a Media ID). |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/uploadslist?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"id": <str>,
"object_id": <str>,
"status_code": <int>,
"uploaded_on": <str>,
"last_update": <str>
},
...
]
id:<str>
|
Upload ID. |
object_id:<str>
|
Object ID involved (could be an Upload ID or a Media ID). |
status_code:<int>
|
Status code of the Upload.
|
uploaded_on:<str>
|
Upload timestamp. |
last_update:<str>
|
Last upload check timestamp. |
Output Examples
[ { "id": "up-ac83be70-a01c-4c18-8cc4-dc0b2676cbb0", "object_id": "MEDIA-ID-1234", "status_code": 2, "uploaded_on": "2015-06-10 17:19:37.239458", "last_update": "2015-06-10 17:20:02.557135" }, { "id": "up-60a70bbd-e111-4d0c-b41f-6e235c434330", "object_id": "MEDIA-ID-1234", "status_code": 101, "uploaded_on": "2015-06-09 11:21:07.735656", "last_update": "2015-06-09 11:22:02.549826" }, { "id": "up-776ae4ec-6904-4da1-afa8-1b68017a524a", "object_id": "MEDIA-ID-5678", "status_code": 6, "uploaded_on": "2015-06-10 17:25:04.673541", "last_update": "2015-06-10 17:26:02.542902" } ]
/speech/status
Returns information about the progress of an uploaded media given an Upload ID. It enables the remote repository to keep track of the automatic uploads and to notice possible processing errors.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Upload ID, returned by the /ingest interface. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/status?id=UPLOAD-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"status_code" : <int> ,
"status_info" : <str> ,
"error_code" : <int> ,
"uploaded_on" : <str> ,
"last_update" : <str> ,
"estimated_time_complete" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
status_code:<int>
|
Status code of the upload.
|
status_info:<str>
|
Detailed information about the status code. |
error_code:<int>
|
Generic error code that identifies the operation that failed within the process, if any. Otherwise null. |
uploaded_on:<str>
|
Upload timestamp. |
last_update:<str>
|
Last status check timestamp. |
estimated_time_complete:<str>
|
Estimated time to complete the whole process. |
Output Examples
{ "rcode": 1, "rcode_description" : "Upload ID [ up-1234 ] does not exist." }
{ "rcode": 0, "rcode_description" : "Upload ID exists.", "status_code": 2, "info": "Transcription in progress. It may take several hours for it to finish.", "uploaded_on": "2014-03-26 19:02:16.174944", "last_update": "2014-03-26 19:03:05.298861" }
/speech/systems
Get a list of all available ASR/MT/TTS Systems that can be applied to transcribe/translate/synthesize a un uploaded media file using the /ingest interface. Subtitle postprocessing modules, to postprocess raw ASR/MT output, are also listed.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/systems?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
"asr": [
{
"lang": <str>,
"id": <int>,
"name": <str>,
"description": <str>
},
...
],
"mt": [
{
"source_lang": <str>,
"target_lang": <str>,
"id": <int>,
"name": <str>,
"description": <str>
},
...
],
"subtitle-postproc": [
{
"lang": <str>,
"id": <int>,
"name": <str>,
"description": <str>
},
...
],
"tts": [
{
"lang": <str>,
"id": <int>,
"name": <str>,
"description": <str>,
"voice_gender": <str>
},
...
]
]
asr:<list:dict>
|
List of all available Automatic Speech Recognition Systems.
|
mt:<list:dict>
|
List of all available Machine Translation Systems.
|
subtitle-postproc:<list:dict>
|
List of all available subtitle postprocessing modules.
|
tts:<list:dict>
|
List of all available Text-To-Speech Systems.
|
|
|
The system ID might be used to explicitly request to the Ingest Service the application of a particular ASR/MT/TTS system. For further information please see Requesting Subtitle Languages). |
Output Examples
{ "asr": [ { "lang": "en", "id": 43, "name": "English ASR System", "description": "" }, { "lang": "es", "id": 22, "name": "Spanish ASR System", "description": "" }, { "lang": "ca", "id": 64, "name": "Catalan ASR System", "description": "" } ], "mt": [ { "source_lang": "ca", "target_lang": "es", "id": 14, "name": "Catalan-Spanish MT System", "description": "" }, { "source_lang": "es" "target_lang": "ca", "id": 11, "name": "Spanish-Catalan MT System", "description": "" }, { "source_lang": "en", "target_lang": "es", "id": 73, "name": "English-Spanish MT System", "description": "" }, { "source_lang": "es" "target_lang": "en", "id": 24, "name": "Spanish-English MT System", "description": "" } ], "subtitle-postproc": [ { "lang": "ca", "id": 102, "name": "Catalan subtitle-postproc module: truecaser + word2num + punctuation restore", "description": "" } ], "tts": [ { "lang": "en", "id": 71, "name": "English TTS System (Female)", "description": "", "voice_gender": "f" } ] }
/speech/list
Get a list of all existing audios and videos in the TLP Database.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/list?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"id": <str>,
"title": <str>,
"language": <str>,
"duration": <int>
},
...
]-
id:
<int>→ Media ID. -
title:
<str>→ Media’s title. -
language:
<str>→ Media language code (ISO-639-1). -
duration:
<int>→ Media length in seconds.
Output Examples
{ { "id": "MEDIA-ID-1234", "title": "I do know nothing", "language": "en", "duration": 86 }, { "id": "MEDIA-ID-6789", "title": "Tyrion Lannister and Daenerys Targaryen: the Royal Wedding.", "language": "en", "duration": 271 } }
/speech/list_fullinfo
Get a list of all existing audios and videos in the TLP Database, plus their
metadata, captions available, and media file locations. Objects are sorted by
ingestion date, from the more recent to the oldest. Please note that the amount
of results returned is limited by the limit parameter. page parameter can be used
to navigate through pages.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
limit |
int |
No |
Limit query results (default: 10) |
|
page |
int |
No |
Page number (default: 1) |
|
external_id |
str |
No |
Search/filter results by external_id (contains) |
|
title |
str |
No |
Search/filter results by title (contains) |
|
date_from |
str |
No |
Return objects ingested after the provided date (included). Must be in "yyyy-mm-dd" or "dd-mm-yyyy" format |
|
date_to |
str |
No |
Return objects ingested before the provided date (included). Must be in "yyyy-mm-dd" or "dd-mm-yyyy" format |
|
sort |
str |
No |
Sorting criterion. Allowed values: title, title:asc, title:desc, external_id, external_id:asc, external_id:desc, date, date:asc, date:desc |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/list_fullinfo?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"total": <int>,
"objects": [
{
"id": <str>,
"metadata": {
"duration": <int>,
"date": <str>,
"language": <str>,
"title": <str>,
"speakers": [
{
"name": <str>
},
...
]
},
"media": [
{
"is_url": <bool>,
"type_code": <int>,
"media_format": <str>,
"location": <str>
},
...
],
"attachments": [
{
"is_url": <bool>,
"type_code": <int>,
"media_format": <str>,
"location": <str>
},
...
],
"audiotracks": [
{
"lang": <str>,
"voice_type": <str>,
"id": <int>,
"location": <str>,
"media_format": <str>,
"audio_type": <str>,
"is_url": <bool>,
"sub_type": <int>,
"description": <str>
},
...
],
"captions": [
{
"lang_code": <str>,
"lang_name": <str>,
"sup_status": <int>,
"sup_ratio": <float>,
"rev_time" : <int>,
"rev_rtf" : <float>,
"system_time" : <int>,
"system_rtf" : <float>
"last_updated" : <str>
},
...
]
},
...
}
total:<int>
|
Total number of objects found in the database. |
objects:<list>
|
List of objects returned in this query, of length limited by the |
id:<str>
|
Object ID. |
metadata:<dict>
|
Media Metadata.
|
media:<list:dict>
|
List of media files available.
|
attachments:<list:dict>
|
List of attachments available.
|
audiotracks:<list:dict>
|
List of available audiotracks.
|
captions:<list:dict>
|
List of available captions.
|
Output Examples
{ "total": 1, "objects": [ { "id": "media-1234", "metadata": { "duration": 86, "date": "2022-03-03", "speakers": [ { "name": "John Snow" } ], "language": "en", "title": "I do know nothing" }, "media": [ { "is_url": true, "type_code": 0, "media_format": "mp4", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/1a4edf93069b3.mp4" }, { "is_url": true, "type_code": 3, "media_format": "jpg", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/d7bbbe4210bd3.jpg" }, { "is_url": true, "type_code": 6, "media_format": "pcm", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/75bae29f33670.pcm" } ], "attachments": [ { "is_url": true, "type_code": 1, "media_format": "txt", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/b3f0bee253651191cdd1f1ee6c865074.txt" }, { "is_url": true, "type_code": 2, "media_format": "txt", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/d41d8cd98f00b204e9800998ecf8427e.txt" } ], "audiotracks": [ { "lang": "es", "voice_type": "tts", "id": 68, "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/audiotrack.es.mp3", "media_format": "mp3", "audio_type": null, "is_url": true, "sub_type": 2, "description": null } ], "captions": [ { "lang_code": "es", "sup_status": 1, "sup_ratio": 61.1650485436893, "rev_time" : 682 , "rev_rtf" : 1.2 , "system_time" : null , "system_rtf" : null , "last_updated": "2022-05-20 16:01:01.670457", "lang_name": "Español" }, { "lang_code": "ca", "sup_status": 0, "sup_ratio": 0, "rev_time" : 0 , "rev_rtf" : 0 , "system_time" : null , "system_rtf" : null , "last_updated": "2022-05-20 16:01:01.670457", "lang_name": "Català" }, { "lang_code": "en", "sup_status": 2, "sup_ratio": 100, "rev_time" : 923 , "rev_rtf" : 1.6 , "system_time" : null , "system_rtf" : null , "last_updated": "2022-05-20 16:01:01.670457", "lang_name": "English" } ] } }
/speech/metadata
Returns metadata and media file locations of a given media ID. For example, this operation is called by the TLP Player to get the main media file location.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/metadata?id=MEDIA-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int> ,
"rcode_description": <str> ,
"mediainfo": {
"language" : <str> ,
"title" : <str> ,
"category" : <str> ,
"duration" : <str> ,
"speakers" : [
{
"name" : <str>
} ,
...
]
} ,
"media": [
{
"is_url" : <bool> ,
"type_code" : <int> ,
"media_format" : <str> ,
"location" : <str>
} ,
...
],
"audiotracks": [
{
"lang": <str>,
"voice_type": <str>,
"id": <int>,
"location": <str>,
"media_format": <str>,
"audio_type": <str>,
"is_url": <bool>,
"sub_type": <int>,
"description": <str>
} ,
...
],
"attachments": [
{
"is_url" : <bool> ,
"type_code" : <int> ,
"media_format" : <str> ,
"location" : <str>
} ,
...
]
}
rcode:<int>
|
Return code of the WS call.
|
rcode_description:<str>
|
Description of the return code (rcode). |
mediainfo:<dict>
|
Media Metadata.
|
media:<list:dict>
|
List of media files available.
|
audiotracks:<list:dict>
|
List of available audiotracks.
|
attachments:<list:dict>
|
List of attachments available.
|
Output Examples
{ "rcode" : 1, "rcode_description" : "Media ID [ 1234-abcd ] does not exist or has no media" }
{ "rcode": 0, "rcode_description": "Media list and info available.", "attachments": [ { "is_url": true, "type_code": 1, "media_format": "txt", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/b3f0bee253651191cdd1f1ee6c865074.txt" }, { "is_url": true, "type_code": 2, "media_format": "txt", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/d41d8cd98f00b204e9800998ecf8427e.txt" } ], "media": [ { "is_url": true, "type_code": 0, "media_format": "mp4", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/1a4edf93069b3.mp4" }, { "is_url": true, "type_code": 3, "media_format": "jpg", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/d7bbbe4210bd3.jpg" }, { "is_url": true, "type_code": 6, "media_format": "pcm", "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/75bae29f33670.pcm" } ], "lectureinfo": { "duration": 86, "speakers": [ { "name": "John Snow" } ], "language": "en", "title": "I do know nothing" }, "audiotracks": [ { "lang": "es", "voice_type": "tts", "id": 68, "location": "http://my-tlp-server.com/data/9/9bc70b33e49c2/audiotrack.es.mp3", "media_format": "mp3", "audio_type": null, "is_url": true, "sub_type": 2, "description": null } ] }
/speech/langs
Returns list of subtitle languages available for a specific media ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/langs?id=MEDIA-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"media_lang" : <str> ,
"locked" : <bool> ,
"langs" : [
{
"lang_code" : <str> ,
"lang_name" : <str> ,
"sup_status" : <int> ,
"sup_ratio" : <float> ,
"sup_wer" : <float> ,
"sup_bleu" : <float> ,
"rev_time" : <int> ,
"rev_rtf" : <float> ,
"system_time" : <int> ,
"system_rtf" : <float> ,
"last_updated" : <str> ,
"audiotracks": [
{
"aid": <int>,
"voice_gender": <str>,
"voice_type": <str>
},
...
]
},
...
]
}
rcode:<int>
|
Return code of the WS call.
|
rcode_description:<str>
|
Description of the return code (rcode). |
media_lang:<str>
|
Language code (ISO-639-1) of the media’s original audio language. |
locked:<bool>
|
Lock status of subtitles. If |
langs:<list:dict>
|
List of languages available.
|
Output Examples
{ "rcode" : 1 , "rcode_description" : "ID 1234-abcd does not exist or has no subtitles" , }
{ "rcode": 0, "rcode_description": "Language list available.", "media_lang": "es", "locked": false, "langs": [ { "lang_code": "es", "sup_status": 1, "sup_ratio": 61.1650485436893, "rev_time" : 682 , "rev_rtf" : 1.2 , "system_time" : null , "system_rtf" : null , "lang_name": "Español", "last_updated": "2022-05-20 16:01:01.670457", "audiotracks": [] }, { "lang_code": "ca", "sup_status": 0, "sup_ratio": 0, "rev_time" : 0 , "rev_rtf" : 0 , "system_time" : null , "system_rtf" : null , "lang_name": "Català", "last_updated": "2022-05-20 16:01:01.670457", "audiotracks": [] }, { "lang_code": "en", "sup_status": 2, "sup_ratio": 100, "rev_time" : 923 , "rev_rtf" : 1.6 , "system_time" : null , "system_rtf" : null , "lang_name": "English", "last_updated": "2022-05-20 16:01:01.670457", "audiotracks": [ { "aid": 12, "voice_gender": "f", "voice_type": "tts" } ] } ] }
/speech/get
Returns subtitles for a specific media ID and language. By default, subtitles are sent in DFXP format, although they can be retrieved in many other formats.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
lang |
str |
Yes |
Language code (ISO 639-1). |
|
format |
int |
No |
Subtitles format.
|
|
session_id |
int |
No |
If full_history=1 (by default), applies to the original subtitle file all confirmed subtitle modifications until the given session ID. Else, if full_history=0, returns all subtitle modifications made only under the given session ID. This option is not compatible with |
|
full_history |
int |
No |
Modifies the behaviour of the session_id option, and determines whether it will be returned the full edit history or just the given edit session. By default full_history=1. |
|
pending_revs |
int |
No |
Apply to the current subtitle file those revisions that are still pending to be reviewed. Allowed values: { |
|
seg_filt_policy |
int |
No |
Segment text filtering policy.
|
|
sel_data_policy |
int |
No |
Subtitle contents to be returned.
|
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/get?id=MEDIA-ID-1234&lang=en&format=2&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
-
DFXP file: Content-Type = application/ttml+xml
-
SRT file: Content-Type = application/x-subrip
-
VTT file: Content-Type = text/vtt
-
TXT file: Content-Type = text/plain
-
JSON file: Content-Type = application/json
-
STL file: Content-Type = application/sla
-
DOCX file: Content-Type = application/vnd.openxmlformats-officedocument.wordprocessingml.document
-
Content-Type = application/json
{
"rcode" : <int> ,
"rcode_description" : <int>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode" : 1 , "rcode_description" : "Media ID [MEDIA-ID-1234] does not exist" }
1
00:08:44,090 --> 00:08:48,680
Good morning, my name is Kit Harington, but people is used to call me John Snow.
2
00:08:48,680 --> 00:08:51,850
Winter is coming, isn't it?/speech/getmod
Get subtitle modifications in JSON format of a given media and session ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
session_id |
int |
No |
Session ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/getmod?id=MEDIA-ID-1234&session_id=327&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int>,
"rcode_description": <str>,
"mods": <json>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
mods:<json>
|
JSON dict including all subtitle modifications, following the same format as the mods parameter of /speech/mod interface. Returns an empty dict if no changes were made in such session_id. |
Output Examples
{ "mods": { "en": { "txt": [ { "sI": 3, "b": 115.8, "e": 137.77, "t": "Good job!" } ], "del": [], "rev_time": 4 }, "es": { "txt": [ { "sI": 3, "b": 115.8, "e": 137.77, "t": "Buen trabajo!" } ], "del": [], "rev_time": 6 } }, "rcode": 0, "rcode_description": "Mod session found, returning modifications in JSON." }
/speech/audiotrack
Sends in binary format an audiotrack file.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
lang |
str |
Yes |
Language code (ISO 639-1). |
|
aid |
int |
Yes |
Audiotrack ID (from /metadata). |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/audiotrack?id=MEDIA-ID-1234&lang=en&aid=428&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
-
A Content-Type different than application/json, typically audio/mpeg (mp3) or audio/wav (wav)
-
Content-Type = application/json
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode" : 1 , "rcode_description" : "Media ID [MEDIA-ID-1234] does not exist" }
/speech/active_sessions
Returns a list of active edit sessions involving a given media ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/active_sessions?id=MEDIA-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int>,
"rcode_description": <str>,
"sessions": [
{
"session_id": <int>,
"session_type": <str>,
"author_id": <str>,
"author_name": <str>,
"author_conf": <int>,
"author_type": <str>,
"started_at": <str>,
"last_update": <str>
},
...
]
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
sessions:<list:dict>
|
List of dicts containing infomation of each active session, if any.
|
Output Examples
{ "rcode_description": "", "rcode": 0, "sessions": [ { "last_update": "2022-06-09 10:37:28.936321", "author_name": "Àlex Pérez", "session_type": "player", "author_id": "aperez", "started_at": "2022-06-09 10:28:08.928397", "author_conf": 100, "session_id": 372, "author_type": "human" }, { "last_update": "2022-06-09 10:37:26.934773", "author_name": "Joan Albert Silvestre", "session_type": "player", "author_id": "jsilvestre", "started_at": "2022-06-09 10:33:16.014103", "author_conf": 100, "session_id": 373, "author_type": "human" } ] }
/speech/start_session
Starts an edition session to send and commit modifications of a subtitles file.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
type |
str |
No |
Session type. Allowed values are: |
|
author_id |
str |
Yes |
Author ID, authorised by the API client, that starts the edition session. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/start_session?id=MEDIA-ID-1234&type=player&author_id=jsnow21&author_conf=90&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int>,
"rcode_description": <str>,
"session_id": <int>,
"session_type": <str>,
"author_id": <str>,
"author_name": <str>,
"author_conf": <int>,
"author_type": <str>,
"started_at": <str>,
"last_update": <str>,
"concurrent_sessions": <list:dict>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
session_id:<int>
|
Session ID. |
session_type:<int>
|
Session type. |
author_id:<str>
|
Author ID that started the session and currently editing the Media ID. |
author_conf:<int>
|
Confidence level of the author ID, from 0 to 100. |
author_name:<int>
|
Author Name. |
author_type:<str>
|
Author Type.
|
started_at:<str>
|
Session start timestamp. |
last_update:<str>
|
Timestamp of the last update (/mod call) made by the user on the session. |
concurrent_sessions:<list:dict>
|
List of other concurrent (active) edit sessions of other users involving the same media ID. |
Output Examples
{ "rcode": 0, "rcode_description": "Session started.", "session_id": 8, "session_type": "player", "author_id": "jsnow21", "author_name": "John Snow", "author_conf": 90, "author_type": "human", "started_at": "2015-07-04 20:44:55.042786", "last_update": "2015-07-04 20:44:55.042786", "concurrent_sessions": [] }
{ "rcode": 4, "rcode_description": "Cannot start mod session: there exist an open mod session for the given media ID.", "session_id": 7, "session_type": "player", "author_id": "olly666", "author_name": "Olly", "author_conf": 100, "author_type": "human", "started_at": "2015-07-04 12:23:15.040186", "last_update": "2015-07-04 20:32:11.892843", "concurrent_sessions": [] }
/speech/session_status
Returns the current status of the given session ID. If it is alive, it updates the last alive timestamp (last_update output key). This interface is commonly used to avoid the automatic end of session due to user inactivity.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
alive |
int |
No |
Alive message type.
|
1 |
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/session_status?id=MEDIA-ID-1234&session_id=8&author_id=jsnow21&author_conf=90&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int>,
"rcode_description": <str>,
"started_at": <str>,
"last_update": <str>,
"last_alive": <str>,
"ended_at": <str>,
"ended_by_id": <str>,
"ended_by_name": <str>,
"ended_by_type": <str>,
"concurrent_sessions": <list:dict>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
started_at:<str>
|
Session start timestamp. |
last_update:<str>
|
Session last update timestamp. |
last_alive:<str>
|
Session last alive timestamp. |
ended_at:<str>
|
Session end timestamp. Will be |
ended_by_id:<str>
|
Author ID of the user that ended this session. Will be |
ended_by_name:<str>
|
Author name of the user that ended this session. Will be |
ended_by_type:<str>
|
Author type of the user that ended this session. Will be
|
concurrent_sessions:<list:dict>
|
List of other concurrent (active) edit sessions of other users involving the same media ID. |
Output Examples
{ "rcode": 0, "rcode_description": "Session alive.", "started_at": "2015-07-04 20:44:55.042786", "last_update": "2015-07-04 21:03:23.017192", "last_alive": "2015-07-04 21:03:51.932841", "ended_at": null, "ended_by_id": null, "ended_by_name": null "ended_by_type": null, "concurrent_sessions": [] }
{ "rcode": 4, "rcode_description": "Session ID 8 is closed.", "started_at": "2015-07-04 20:44:55.042786", "last_update": "2015-07-04 20:44:55.042786", "last_alive": "2015-07-04 20:45:03.016531", "ended_at": "2015-07-04 22:28:51.075672", "ended_by_id": "lord_stark1", "ended_by_name": "Eddard Stark", "ended_by_type": "human", "concurrent_sessions": [] }
/speech/mod
Send and commit modifications of subtitles files made by a user under a session ID returned by /start_session interface.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
mods |
json |
Yes |
JSON Dictionary containing as many key-values as subtitle languages has been modified, being keys a ISO 639-1 language code of the subtitle languages edited, and values a dictionary containing the following keys:
Note: When using the GET method with multiple GET parameters, this JSON object must be encoded in Base64. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/mod?id=MEDIA-ID-1234&session_id=8&language=en&author_id=jsnow21&author_conf=90&mod=eyAiZW4iOiB7InR4dCI6WyB7InNJIjoxNiwgImIiOjg3Ljk2LCAiZSI6OTEuMzcsICJ0IjoiU2hlIHRvbGQgbWU6IFlvdSBrbm93IG5vdGhpbmcsIEpvaG4gU25vdyJ9IF0sICJkZWwiOlszLDddfSwgImVzIjogeyJkZWwiOls5XSwgInR4dCI6W119IH0=&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"details": [
{
"language": <str>,
"rcode_description": <str>,
"rcode": <int>,
"errors": [
{ "ind":<int>,
"sI":<int>,
"code":<int>,
"info":<str>},
...
]
},
...
]
}
rcode:<int>
|
Endpoint return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
details:<array:dict>
|
List of dicts for every subtitle language modifications if format errors were found (rcode
|
Output Examples
{ "rcode" : 0 , "rcode_description" : "Changes successfully saved." }
{ "rcode" : 4 , "rcode_description" : "Session ID [ 8 ] is closed, changes have been backuped. Please contact system administrator." }
{ "rcode_description": "Modifications for some subtitle languages were successfully saved, but other failed. Please see 'details' key.", "rcode": 8, "details": [ { "rcode_description": "The given media ID does not have 'en' subtitles.", "rcode": 10, "language": "en", "errors":[] }, { "rcode_description": "Changes successfully saved.", "rcode": 0, "language": "es", "errors":[] }, { "rcode_description": "Errors found on 3 subtitle modifications", "rcode": 1, "language": "ca", "errors": [ { "ind": 0, "info": "Segment begin 'e' must be greater than zero", "sI": 1, "code": 8 }, { "ind": 1, "info": "Segment end 'e' must be greater than segment begin 'b'", "sI": 2, "code": 9 }, { "ind": 2, "info": "'txt' elements must include the following keys: 'sI', 'b', 'e', 't'", "sI": 3, "code": 4 } ] } ] }
/speech/mod_scenes
Send and commit modifications of scene changes made by a user under a session ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
scene_changes |
json |
Yes |
List of floats, in JSON format, corresponding to scene change timestamps (in seconds). Note: When using the GET method with multiple GET parameters, this JSON object must be encoded in Base64. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/mod_scenes?id=MEDIA-ID-1234&session_id=8&language=en&author_id=jsnow21&author_conf=90&scene_changes=WzEzLjExLCA1My4yLCA4Ny45NiwgOTEuMzdd&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str> ,
}
rcode:<int>
|
Endpoint return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode" : 0 , "rcode_description" : "Changes successfully saved." }
/speech/end_session
Ends an open edition session. Depending on the confidence of the user, editions are directly stored in the corresponding DFXP files or are left for revision.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, that closes the session. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
force |
int |
No |
Force end session when user and/or author_id are not the owners.
|
1 |
regenerate |
int |
No |
Request regeneration of subtitles and/or synthesized audiotracks immediately after closing the session.
|
0 |
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/end_session?id=MEDIA-ID-1234&session_id=8&author_id=jsnow21&author_conf=90&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode": 0, "rcode_description": "Session succesfully closed." }
/speech/lock
Allow/disallow regular users to send subtitles modifications for an specific Media ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
lock |
int |
Yes |
Lock action:
|
|
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. Must be 100. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/lock?id=MEDIA-ID-1234&lock=1&author_id=lord_stark1&author_conf=100&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode" : 0 , "rcode_description" : "Subtitles successfully locked." }
/speech/edit_history
Returns a list of all edit sessions carried out over an specific Media ID.
Session edits can be applied to a subtitles file calling the /get
interface and passing to it the proper Session ID to the session_id
parameter.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/edit_history?id=MEDIA-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode_description": <str>,
"rcode": <int>,
"edit_history": [
{
"session_id": <int>,
"author_id": <str>,
"author_conf": <int>,
"author_name": <str>,
"started_at": <str>,
"ended_at": <str>,
"timestamp": <str>,
"requires_revision": <bool>,
"revised": <bool>,
"revised_at": <str>,
"revised_by_id": <int>,
"revised_by_name": <str>,
"revised_via": <str>,
"revised_in_session_id": <int>,
"edit_stats": <dict>
},
...
]
}
rcode:<int>
|
Return code.
|
edit_history:<array:dict>
|
List of dictionaries containing information about each edit session.
|
Output Examples
{ "rcode_description": "Edit history available.", "rcode": 0, "edit_history": [ { "session_id": 9, "author_id": "lord_stark1", "author_conf": 100, "author_name": "Eddard Stark", "started_at": "2015-07-05 11:46:19.124615", "ended_at": "2015-07-05 12:14:15.824233", "timestamp": "2015-07-05 12:14:15.824233", "requires_revision": false, "revised": null, "revised_at": null, "revised_by_id": null, "revised_by_name": null, "revised_via": null, "revised_in_session_id": null, "edit_stats": { "en": { "del_segs": 2, "edit_segs": 67, "rev_time": 134, "rev_rtf": 2.0, "edit_time": 631.97, "edit_time_percent": 100.00 }, "es": { "del_segs": 3, "edit_segs": 5, "rev_time": 65, "rev_rtf": 2.0, "edit_time": 32.52, "edit_time_percent": 5.12 } } }, { "session_id": 8, "author_id": "jsnow21", "author_conf": 90, "author_name": "John Snow", "timestamp": "2015-07-04 21:23:07.000031", "requires_revision": true, "revised": true, "revised_at": "2015-07-05 12:14:15.824233", "revised_by_id": "lord_stark1", "revised_by_name": "Eddard Stark", "revised_via": "mark_revised", "revised_in_session_id": 9, "edit_stats": { "en": { "del_segs": 0, "edit_segs": 21, "edit_time": 197.23, "edit_time_percent": 31.74 } } }, { "session_id": 7, "author_id": "olly666", "author_conf": 20, "author_name": "Olly", "timestamp": "2015-07-02 18:53:59.565720", "requires_revision": true, "revised": false, "revised_at": null, "revised_by_id": null, "revised_by_name": null, "revised_via": null, "revised_in_session_id": null, "edit_stats": { "en": { "del_segs": 4, "edit_segs": 3, "edit_time": 13.22, "edit_time_percent": 2.58 } } } ] }
/speech/revisions
Returns a list of all edit sessions for all API user’s media files that are pending to be revised.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/speech/revisions?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"media_id": <str>,
"session_id": <int>,
"author_id": <str>,
"author_conf": <int>,
"author_name": <str>,
"timestamp": <str>,
"edit_stats": <dict>
},
...
]
media_id:<str>
|
Media ID. |
session_id:<str>
|
Session ID. |
author_id:<str>
|
Author ID owner of the session. |
author_conf:<int>
|
Confidence level of the author, from 0 to 100. |
author_name:<str>
|
Author name. Can be |
timestamp:<str>
|
Session end timestamp. |
edit_stats:<dict>
|
Dictionary containing statistics of the session’s edits. Each dictionary key is a language code (ISO-639-1) whose value is another dictionary that contains edit statistics of the corresponding subtitles language. These dictionaries feature the following keys:
|
Output Examples
[ { "media_id": "MEDIA-ID-1234", "session_id": 8, "author_id": "jsnow21", "author_conf": 90, "author_name": "John Snow", "timestamp": "2015-07-04 21:23:07.000031", "edit_stats": { "en": { "del_segs": 2, "edit_segs": 1, "edit_time": 3.41, "edit_time_percent": 1.97 } } } ]
/speech/mark_revised
Mark/unmark an edition session as revised.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Media ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, who revised the changes made in the Session ID session_id. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author. Must be |
|
revision_session_id |
int |
No |
Session ID under which the given Author ID revised the changes made in the Session ID session_id. |
12 |
unmark |
int |
No |
Do the inverse process: delete revised mark.
|
1 |
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/mark_revised?id=MEDIA-ID-1234&session_id=8&author_id=lord_stark1&author_conf=100&revision_session_id=12&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode": 0, "rcode_description": "Session ID marked as revised." }
/speech/accept
Accept modifications of one or more pending edit sessions without having to revise them. Modifications are commited into the corresponding subtitles files.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Comma-separated list of Session IDs whose edits are meant to be accepted by the given Author ID. |
|
author_id |
str |
Yes |
Author ID, authorised by the API client, who revised the changes made in the Session ID session_id. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author. Must be |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/accept?id=27,43,82,121&&author_id=lord_stark1&author_conf=100&revision_session_id=12&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
Returns a list of dictionaries, one for each Session ID.
[
{
"session_id": <int>,
"rcode" : <int> ,
"rcode_description" : <str>
},
...
]
session_id:<int>
|
Session ID. |
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
[ { "rcode_description": "Session ID does not exist.", "rcode": 1, "session_id": 27 }, { "rcode_description": "Session ID did not require revision.", "rcode": 4, "session_id": 43 }, { "rcode_description": "Session ID already revised.", "rcode": 5, "session_id": 82 }, { "rcode_description": "Changes from Session ID successfully accepted.", "rcode": 0, "session_id": 121 } ]
/speech/reject
Reject modifications of one or more pending edit sessions without having to revise them.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Comma-separated list of Session IDs whose edits are meant to be accepted by the given Author ID. |
|
author_id |
str |
Yes |
Author ID, authorised by the API client, who revised the changes made in the Session ID session_id. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author. Must be |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/speech/reject?id=27,43,82,121&&author_id=lord_stark1&author_conf=100&revision_session_id=12&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
Returns a list of dictionaries, one for each Session ID.
[
{
"session_id": <int>,
"rcode" : <int> ,
"rcode_description" : <str>
},
...
]
session_id:<int>
|
Session ID. |
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
[ { "rcode_description": "Session ID does not exist.", "rcode": 1, "session_id": 27 }, { "rcode_description": "Session ID did not require revision.", "rcode": 4, "session_id": 43 }, { "rcode_description": "Session ID already revised.", "rcode": 5, "session_id": 82 }, { "rcode_description": "Changes from Session ID successfully rejected.", "rcode": 0, "session_id": 121 } ]
Appendix F: Web Service API: /text API specifications
Please note that all the following interfaces will share a common prefix: /text.
|
/ingest
|
Upload document (text/document) files and metadata to the TLP Server to be automatically translated. |
|
/uploadslist
|
Get a list of all the user’s uploads. |
|
/status
|
Check the current status of a specific upload ID. |
|
/systems
|
Get a list of all available Machine Translation systems that can be applied to translate a document file. |
|
/list
|
Get a list of all existing documents in the Database. |
|
/metadata
|
Get metadata for a given document ID. |
|
/langs
|
Get a list of all language translations available for a given document ID. |
|
/get
|
Download the latest version of the translated document file for a given document ID and language. |
|
/start_session
|
Starts an edition session to send and commit modifications of a translation file. |
|
/session_status
|
Returns the current status of the given session ID. |
|
/mod
|
Send and commit translation corrections under an edit session. |
|
/end_session
|
Ends an open edition session, and depending on the confidence of the user, editions are directly stored in the corresponding translation files or left for revision. |
|
/lock
|
Allow/disallow regular users to send modifications for an specific document ID. |
|
/edit_history
|
Returns a list of all edit sessions that involved an specific document ID. |
|
/revisions
|
Returns a list of all edit sessions for all API user’s document files that are pending to be revised. |
|
/mark_revised
|
Mark/unmark as revised an specific edit session ID, typically from another Session ID on the TLP Translation Editor. |
|
/accept
|
Accept modifications of one or more pending edit sessions without having to revise them. Modifications are commited into the corresponding translation files. |
|
/reject
|
Reject modifications of one or more pending edit sessions without having to revise them. |
/text/ingest
This interface allows the client to upload document files to the platform so they can be automatically translated into several languages by the Ingest Service. The uploaded documents are bundled into a non-compressed ZIP file called Document Package (MPF). The Web Service stores the Document Packages in the server and returns an Upload ID, which can be used afterwards to check the upload progress via the /status interface.
|
|
If you are developing your own API client, it is recommended to enable the Test Mode of the Ingest Service when performing call tests to this interface. Please refer to the Manifest JSON File Specification. |
The /ingest interface is split into four sub-interfaces, every one devoted to implement the four operation types supported by the Ingest Service:
Every sub-interface has different input specifications, please refer to each sub-section. Particularly, the /new and /update operations require as input a base64-encoded Manifest JSON string (please see Manifest JSON sub-section). In case any document files have to be uploaded to the TLP Server, those files have to be declared in the Manifest JSON string, and attached to the HTTP query as a Document Package file (please see Document Package sub-section). Finally, all sub-interfaces share the same output specifications, please see the Output sub-section.
Manifest JSON
The Manifest JSON is a JSON string that provides several metadata required by the /new and /update operations. For example, on new operations it must describe document attributes such as ID, title or language. Also, it is used to tell the Ingest Service that one or more document files have been uploaded, bundled into a Document Package file.
Manifest file JSON Specification
{
"language" : <str> ,
"documents" : [
{
"external_id" : <str> ,
"title" : <str> ,
"filename" : <str> ,
"fileformat" : <str> ,
"md5" : <str> ,
"url" : <str>
} ,
...
],
"requested_langs": <dict> ,
"generate" : <bool> ,
"re-generate": <bool> ,
"force": <bool> ,
"test_mode" : <bool>
}-
language:
<str>→ Document(s)' language code in ISO 639-1 format (e.g. "en", "es"). -
documents:
<list:dict>→ List of documents to be translated.<dict>keys:-
external_id:
<str>→ Document ID (typically an internal ID in the client’s document repository database) used to identify the document in further queries to the Web Service. -
title:
<str>→ Title of the document. -
filename:
<str>→ File name of the document file. -
fileformat:
<str>→ Format of the document file (see Allowed document formats). -
md5:
<str>→ MD5 checksum of the document file. -
url:
<str>→ URL to the main document file. If a url field is given, then fields filename, fileformat and md5 are ignored.
-
-
requested_langs:
<dict>→ Request translation languages along with some advanced options. Please see Requesting translation languages (optional). -
generate:
<bool>→ Enable/disable translation technologies (optional, defaulttrue). -
re-generate:
<bool>→ On update operation: request regeneration of translations for the provided list of Document IDs. In this case, only the external_id key is required for each documents item (optional, defaultfalse). -
force:
<bool>→ On update operation: Force regeneration of automatic subtitles even if there exist human-supervised subtitles (optional, defaultfalse). -
test_mode:
<bool>→ Enable/Disable the Test Mode of the Ingest Service. When enabled, the uploaded document(s) will be available immediately with an empty translation file. This feature is very useful when executing integration tests with the /ingest interface (optional, defaultfalse).
Requesting translation languages
The requested_langs option, as stated before, is used to request translation languages, specifying advanced translation options. requested_langs is a JSON dictonary in which keys are ISO 639-1 language codes (e.g. "en", "es"), and values are dictionaries with advanced options.
"requested_langs": { "es": {}, "en": {} }
The example above means: "Generate Spanish and English translations using default options in all cases".
Advanced options:
-
sid:
<int>→ Specify which System will be applied to generate the translation file. If not specified, the default system is used. -
tlpath:
<list>→ Explicitly declare a Translation Path. This is useful to generate translations to a language which is not featured directly from the spoken language, using intermediate translation languages. It is declared as an ordered list of dictionaries, where each dictionary specifies the target language code l of the step, and optionally the System ID sid to apply.The example below shows how to request a Catalan (
ca) translation from the document language (XX) using English (en) and Spanish (es) as intermediate languages, thus defining the following translation path:XX->En->Es->Ca. The intermediateEn->Estranslation is generated using System ID 3."requested_langs": { "ca": { "tlpath": [ { "l":"en" }, { "l":"es", "sid":3}, { "l":"ca"} ] } }
If this option is not specified, the Ingest Service will assume that a direct translation from the spoken language is requested.
Allowed document formats
Below follows a table in which are listed the document file formats that are typically allowed to be uploaded to a standard Ingest Service.
| File Format | Description |
|---|---|
txt |
Plain text |
html |
HTML file |
doc |
MS Word File |
docx |
MS Word XML File |
Document Package
A Document Package File is an uncompressed ZIP file that contains several document files declared in the Manifest JSON data sent to the /ingest/new or /ingest/update interfaces. All files must be placed in the root on the ZIP package (not inside folders or sub-folders).
Output
All four sub-interfaces share a common output specification, described as follows:
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"id" : <str> ,
"hash" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
id:<str>
|
Upload ID, which can be used afterwards to check the progress of the upload via the /status interface. |
hash:<str>
|
Internal document hash ID. |
Output Examples
{ "rcode" : 0, "rcode_description" : "Ingestion complete", "id" : "UPLOAD-ID-1234" "hash" : "433e11c295c51b94a074a" }
/text/ingest/new
New document operation.
Input
In this operation only the POST method is allowed (Content-Type: multipart/form-data). Input data is divided in two fields:
-
json: Query parameters encoded in a JSON string (Content-Type: application/json)Parameter name Type Required Description Example manifest
json
Yes
Manifest JSON. See particular specifications for this operation.
[See this example]user
str
Yes
TLP Username / API Username.
tluserauth_token
str
Yes
Authentication token for the provided
user.edbab44c3a3f1ca8db4de8277a3b -
pkg(optional): A Document Package zip file (Content-Type: application/zip).
Manifest JSON data
Below is described how to properly set up a Manifest JSON string for New document operations.
Required inputs:
-
At least one document file to be translated in the documents section.
Behavior changes with optional inputs
-
requested_langs option:
-
Not provided: The document(s) won’t be translated.
-
Provided: Actions that can be inferred from this option will be executed.
-
Call examples
-
JSON string:
{ "user": "tluser", "key": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "language": "en", "documents": [ { "external_id": "9abc7230fe36a18b885c", "title": "To know something or not to know nothing: A brief essay about knowledge.", "url": "http://my-document-server.com/path/to/my/document.html" } ], "requested_langs": { "ca":{}, "es":{} } } }
-
HTTP Call to /ingest/new (note that a Document Package file is not required in this case).
http://my-tlp-server.com/api/text/ingest/new + POST data (JSON string goes in the "json" field)
/text/ingest/update
Update document operation.
Input
In this operation only the POST method is allowed (Content-Type: multipart/form-data). Input data is divided in two fields:
-
json: Query parameters encoded in a JSON string (Content-Type: application/json)Parameter name Type Required Description Example manifest
json
Yes
Manifest JSON. See particular specifications for this operation.
[See this example]user
str
Yes
TLP Username / API Username.
tluserauth_token
str
Yes
Authentication token for the provided
user.edbab44c3a3f1ca8db4de8277a3b -
pkg(optional): A Media Package zip file (Content-Type: application/zip).
Manifest JSON data
Below is described how to properly set up a Manifest JSON string for Update document operations.
Required inputs:
-
One or more document file(s) in documents section when updating original document(s), plus the language attribute.
or
-
One or more document IDs in the re-generate option.
Please note that the documents and re-generate keys cannot be used together.
|
|
To generate new translation languages, use the re-generate option combined with a proper setting of the requested_langs option. |
In all cases, supplied external_id values (Document IDs) must exist.
Behavior changes with optional inputs
-
requested_langs option:
-
Not provided: The ingest service will attempt to re-generate all existing translations.
-
Provided: Actions that can be inferred from this option will be executed. Actions that involve the re-generation of translations that have already been edited or supervised by users won’t be executed, unless the force option is set to
true.
-
Call examples
-
JSON string:
{ "user": "tluser", "key": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "documents": [ { "external_id": "DOCUMENT-ID-1234"}, { "external_id": "DOCUMENT-ID-5678"} ] , "re-generate": true } }
-
HTTP Call to /ingest/update (note that no Document Package file is required).
http://my-tlp-server.com/api/text/ingest/update + POST data (JSON string goes in the "json" field)
-
JSON string:
{ "user": "tluser", "key": "edbab44c3a3f1ca8db4de8277a3b", "manifest": { "documents": [ { "external_id": "9abc7230fe36a18b885c", "title": "To know something or not to know nothing: A brief essay about knowledge (NEW VERSION).", "url": "http://my-document-server.com/path/to/my/document.new.html" } ], "requested_langs": { "ca":{}, "es":{} } } }
-
HTTP Call to /ingest/update, including a Document Package file via POST.
http://my-tlp-server.com/api/text/ingest/update + POST data (JSON string goes in the "json" field, Media Package file in the "pkg" field)
/text/ingest/delete
Delete document operation.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
mode |
str |
No |
Delete mode. * * |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/ingest/delete?id=DOCUMENT-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3b/text/ingest/cancel
Cancel upload operation.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Upload ID, returned by the /ingest interface. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/ingest/cancel?id=UPLOAD-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3b/text/uploadslist
Returns a list of all user’s uploads.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
object_id |
str |
No |
Get list of uploads involving the provided object ID (could be an Upload ID or a Document ID). |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/uploadslist?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"id": <str>,
"object_id": <str>,
"status_code": <int>,
"uploaded_on": <str>,
"last_update": <str>
},
...
]
id:<str>
|
Upload ID. |
object_id:<str>
|
Object ID involved (could be an Upload ID or a Document ID). |
status_code:<int>
|
Status code of the Upload.
|
uploaded_on:<str>
|
Upload timestamp. |
last_update:<str>
|
Last upload check timestamp. |
Output Examples
[ { "id": "up-ac83be70-a01c-4c18-8cc4-dc0b2676cbb0", "object_id": "DOCUMENT-ID-1234", "status_code": 2, "uploaded_on": "2015-06-10 17:19:37.239458", "last_update": "2015-06-10 17:20:02.557135" }, { "id": "up-60a70bbd-e111-4d0c-b41f-6e235c434330", "object_id": "DOCUMENT-ID-1234", "status_code": 101, "uploaded_on": "2015-06-09 11:21:07.735656", "last_update": "2015-06-09 11:22:02.549826" }, { "id": "up-776ae4ec-6904-4da1-afa8-1b68017a524a", "object_id": "DOCUMENT-ID-5678", "status_code": 3, "uploaded_on": "2015-06-10 17:25:04.673541", "last_update": "2015-06-10 17:26:02.542902" } ]
/text/status
Returns information about the progress of an upload ID. It enables the remote repository to keep track of the automatic uploads and to notice possible processing errors.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Upload ID, returned by the /ingest interface. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/status?id=UPLOAD-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"status_code" : <int> ,
"info" : <str> ,
"error_code" : <int> ,
"uploaded_on" : <str> ,
"last_update" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
status_code:<int>
|
Status code of the Upload.
|
info:<str>
|
Detailed information about the status code. |
error_code:<int>
|
Generic error code that identifies the operation that failed within the process, if any. Otherwise null. |
uploaded_on:<str>
|
Upload timestamp. |
last_update:<str>
|
Last status check timestamp. |
Output Examples
{ "rcode": 1, "rcode_description" : "Upload ID [ up-1234 ] does not exist." }
{ "rcode": 0, "rcode_description" : "Upload ID exists.", "status_code": 2, "info": "Translation(s) in progress. It may take several hours for it to finish.", "uploaded_on": "2014-03-26 19:02:16.174944", "last_update": "2014-03-26 19:03:05.298861" }
/text/systems
Get a list of all available MT Systems that can be applied to translate the uploaded document file(s) using the /ingest interface.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/systems?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
"mt": [
{
"source_lang": <str>,
"target_lang": <str>,
"id": <int>,
"name": <str>,
"description": <str>
},
...
]
]
mt:<list:dict>
|
List of all available Machine Translation Systems.
|
|
|
The system ID might be used to explicitly request to the Ingest Service the application of a particular MT system. For further information please see Requesting Subtitle Languages). |
Output Examples
{ "mt": [ { "source_lang": "ca", "target_lang": "es", "id": 14, "name": "Catalan-Spanish MT System", "description": "" }, { "source_lang": "es" "target_lang": "ca", "id": 11, "name": "Spanish-Catalan MT System", "description": "" }, { "source_lang": "en", "target_lang": "es", "id": 73, "name": "English-Spanish MT System", "description": "" }, { "source_lang": "es" "target_lang": "en", "id": 24, "name": "Spanish-English MT System", "description": "" } ] }
/text/list
Get a list of all existing documents in the TLP Database.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/list?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"id": <str>,
"title": <str>,
"language": <str>,
"format": <str>,
"sentences": <int>,
"words": <int>,
"characters": <int>
},
...
]-
id:
<int>→ Document ID. -
title:
<str>→ Document’s title. -
language:
<str>→ Document language code (ISO-639-1). -
format:` → Document file format.
-
sentences:
<int>→ Document length in sentences. -
words:
<int>→ Document length in words. -
characters:
<int>→ Document length in characters.
Output Examples
{ { "id": "DOCUMENT-ID-1234", "title": "I do know nothing", "language": "en", "format": "html", "sentences": 86, "words": 916, "characters": 5701 }, { "id": "DOCUMENT-ID-6789", "title": "Tyrion Lannister and Daenerys Targaryen: the Royal Wedding.", "language": "en", "format": "docx", "sentences": 271, "words": 2953, "characters": 14031 } }
/text/metadata
Returns metadata and document file locations of a given document ID. For example, this operation is called by the TLP Translation Editor to get the main document file location.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/metadata?id=DOCUMENT-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int> ,
"rcode_description": <str> ,
"info": {
"title": <str> ,
"language": <str > ,
"format": <str> ,
"sentences": <int> ,
"words": <int> ,
"characters": <int>
}
}
rcode:<int>
|
Return code of the WS call.
|
rcode_description:<str>
|
Description of the return code (rcode). |
info:<dict>
|
Document metadata.
|
Output Examples
{ "rcode" : 1, "rcode_description" : "Document ID [ 1234-abcd ] does not exist or has no document" }
{ "rcode": 0, "rcode_description": "Document info available.", "info": { "title": "DOCUMENT-ID-1234", "language": "en", "format": "html", "sentences": 86, "words": 916, "characters": 5701 } }
/text/langs
Returns list of translations (languages) available for a specific document ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/langs?id=DOCUMENT-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"document_lang" : <str> ,
"locked" : <bool> ,
"langs" : [
{
"lang_code" : <str> ,
"lang_name" : <str> ,
"sup_status" : <int>
"sup_ratio" : <float>
},
...
]
}
rcode:<int>
|
Return code of the WS call.
|
rcode_description:<str>
|
Description of the return code (rcode). |
document_lang:<str>
|
Language code (ISO-639-1) of the document language. |
locked:<bool>
|
Lock status of translations. If |
langs:<list:dict>
|
List of languages available.
|
Output Examples
{ "rcode" : 1 , "rcode_description" : "ID 1234-abcd does not exist or has no translations" , }
{ "rcode": 0, "rcode_description": "Language list available.", "document_lang": "es", "locked": false, "langs": [ { "lang_code": "es", "sup_status": 2, "sup_ratio": 61.1650485436893, "lang_name": "Español" }, { "lang_code": "ca", "sup_status": 1, "sup_ratio": 0, "lang_name": "Català" }, { "lang_code": "en", "sup_status": 3, "sup_ratio": 100, "lang_name": "English" } ] }
/text/get
Returns translations for a specific document ID and language.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
lang |
str |
Yes |
Language code (ISO 639-1). |
|
format |
int |
No |
Format.
|
|
session_id |
int |
No |
Load translation modifications from the given session ID (if any). If format=2, modified sentences will include the highlight attribute ( |
|
sel_data_policy |
int |
No |
Subtitle contents to be returned.
|
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/get?id=DOCUMENT-ID-1234&lang=ca&format=2&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
-
On its original format
-
TXT file: Content-Type = text/plain
-
DTLX file: Content-Type = application/xml
-
Content-Type = application/json
{
"rcode" : <int> ,
"rcode_description" : <int>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode" : 1 , "rcode_description" : "Document ID [DOCUMENT-ID-1234] does not exist" }
/text/start_session
Starts an edition session to send and commit modifications of a translated document file. Edition sessions are a mechanism devoted to avoid race conditions between different users when editing a translated file.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
author_id |
str |
Yes |
Author ID, authorised by the API client, that starts the edition session. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/start_session?id=DOCUMENT-ID-1234&author_id=jsnow21&author_conf=90&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int>,
"rcode_description": <str>,
"session_id": <int>,
"author_id": <str>,
"author_name": <str>,
"author_conf": <int>,
"author_type": <str>,
"started_at": <str>,
"last_update": <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
session_id:<int>
|
Session ID. |
author_id:<str>
|
Author ID that started the session and currently editing the Document ID. |
author_conf:<int>
|
Confidence level of the author ID, from 0 to 100. |
author_name:<int>
|
Author Name. |
author_type:<str>
|
Author Type.
|
started_at:<str>
|
Session start timestamp. |
last_update:<str>
|
Timestamp of the last update (/mod call) made by the user on the session. |
Output Examples
{ "rcode": 0, "rcode_description": "Session started.", "session_id": 8, "author_id": "jsnow21", "author_name": "John Snow", "author_conf": 90, "author_type": "human", "started_at": "2015-07-04 20:44:55.042786", "last_update": "2015-07-04 20:44:55.042786", }
{ "rcode": 4, "rcode_description": "Cannot start mod session: there exist an open mod session for the given document ID.", "session_id": 7, "author_id": "olly666", "author_name": "Olly", "author_conf": 100, "author_type": "human", "started_at": "2015-07-04 12:23:15.040186", "last_update": "2015-07-04 20:32:11.892843" }
/text/session_status
Returns the current status of the given session ID. If it is alive, it updates the last alive timestamp (last_update output key). This interface is commonly used to avoid the automatic end of session due to user inactivity.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
alive |
int |
No |
Alive message type.
|
1 |
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/session_status?id=DOCUMENT-ID-1234&session_id=8&author_id=jsnow21&author_conf=90&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode": <int>,
"rcode_description": <str>,
"started_at": <str>,
"last_update": <str>,
"last_alive": <str>,
"ended_at": <str>,
"ended_by_id": <str>,
"ended_by_name": <str>,
"ended_by_type": <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
started_at:<str>
|
Session start timestamp. |
last_update:<str>
|
Session last update timestamp. |
last_alive:<str>
|
Session last alive timestamp. |
ended_at:<str>
|
Session end timestamp. Will be |
ended_by_id:<str>
|
Author ID of the user that ended this session. Will be |
ended_by_name:<str>
|
Author name of the user that ended this session. Will be |
ended_by_type:<str>
|
Author type of the user that ended this session. Will be
|
Output Examples
{ "rcode": 0, "rcode_description": "Session alive.", "started_at": "2015-07-04 20:44:55.042786", "last_update": "2015-07-04 21:03:23.017192", "last_alive": "2015-07-04 21:03:51.932841", "ended_at": null, "ended_by_id": null, "ended_by_name": null "ended_by_type": null }
{ "rcode": 4, "rcode_description": "Session ID 8 is closed.", "started_at": "2015-07-04 20:44:55.042786", "last_update": "2015-07-04 20:44:55.042786", "last_alive": "2015-07-04 20:45:03.016531", "ended_at": "2015-07-04 22:28:51.075672", "ended_by_id": "lord_stark1", "ended_by_name": "Eddard Stark", "ended_by_type": "human" }
/text/mod
Send and commit modifications of a translation file made by a user under a session ID returned by /start_session interface.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
mods |
json |
Yes |
JSON Dictionary containing as many key-values as subtitle languages has been modified, being keys a ISO 639-1 language code of the subtitle languages edited, and values a dictionary containing the following keys:
Note: When using the GET method with multiple GET parameters, this JSON object must be encoded in Base64. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/mod?id=DOCUMENT-ID-1234&session_id=8&language=en&author_id=jsnow21&author_conf=90&mod=eyAiY2EiOiB7InR4dCI6WyB7InNJIjoxNiwgInQiOiJTaGUgdG9sZCBtZTogWW91IGtub3cgbm90aGluZywgSm9obiBTbm93In0gXX0gfQ==Output
{
"rcode" : <int> ,
"rcode_description" : <str> ,
"details": [
{
"language": <str>,
"rcode_description": <str>,
"rcode": <int>
},
...
]
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
details:<array:dict>
|
List of dicts for every subtitle language modifications if format errors were found (rcode |
Output Examples
{ "rcode" : 0 , "rcode_description" : "Changes successfully saved." }
{ "rcode" : 4 , "rcode_description" : "Session ID [ 8 ] is closed, changes have been backuped. Please contact system administrator." }
{ "rcode_description": "Modifications for some translations were successfully saved, but other failed. Please see 'details' key.", "rcode": 8, "details": [ { "rcode_description": "The given document ID does not have 'en' translations.", "rcode": 10, "language": "en" }, { "rcode_description": "Changes successfully saved.", "rcode": 0, "language": "es" } ] }
/text/end_session
Ends an open edition session. Depending on the confidence of the user, editions are directly stored into the corresponding DTLX files or are left for revision.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, that closes the session. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. |
|
force |
int |
No |
Force end session when user and/or author_id are not the owners.
|
1 |
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/end_session?id=DOCUMENT-ID-1234&session_id=8&author_id=jsnow21&author_conf=90&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode": 0, "rcode_description": "Session succesfully closed." }
/text/lock
Allow/disallow regular users to send translation modifications for an specific Document ID.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
lock |
int |
Yes |
Lock action:
|
|
author_id |
str |
Yes |
Author ID, authorised by the API client, owner of the session_id. |
|
author_conf |
int |
Yes |
Confidence level of the author, from 0 to 100. Must be 100. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/lock?id=DOCUMENT-ID-1234&lock=1&author_id=lord_stark1&author_conf=100&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode" : 0 , "rcode_description" : "Subtitles successfully locked." }
/text/edit_history
Returns a list of all edit sessions carried out over an specific Document ID.
Session edits can be applied to a translation file calling the /get
interface and passing to it the proper Session ID to the session_id
parameter.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/edit_history?id=DOCUMENT-ID-1234&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode_description": <str>,
"rcode": <int>,
"edit_history": [
{
"session_id": <int>,
"author_id": <str>,
"author_conf": <int>,
"author_name": <str>,
"timestamp": <str>,
"requires_revision": <bool>,
"revised": <bool>,
"revised_at": <str>,
"revised_by_id": <int>,
"revised_by_name": <str>,
"revised_via": <str>,
"revised_in_session_id": <int>,
"edit_stats": <dict>
},
...
]
}
rcode:<int>
|
Return code.
|
edit_history:<array:dict>
|
List of dictionaries containing information about each edit session.
|
Output Examples
{ "rcode_description": "Edit history available.", "rcode": 0, "edit_history": [ { "session_id": 9, "author_id": "lord_stark1", "author_conf": 100, "author_name": "Eddard Stark", "timestamp": "2015-07-05 12:14:15.824233", "requires_revision": false, "revised": null, "revised_at": null, "revised_by_id": null, "revised_by_name": null, "revised_via": null, "revised_in_session_id": null, "edit_stats": { "en": { "edit_sents": 67, "edit_sents_percent": 100.00 }, "es": { "edit_sents": 5, "edit_sents_percent": 5.12 } } }, { "session_id": 8, "author_id": "jsnow21", "author_conf": 90, "author_name": "John Snow", "timestamp": "2015-07-04 21:23:07.000031", "requires_revision": true, "revised": true, "revised_at": "2015-07-05 12:14:15.824233", "revised_by_id": "lord_stark1", "revised_by_name": "Eddard Stark", "revised_via": "mark_revised", "revised_in_session_id": 9, "edit_stats": { "en": { "edit_sents": 21, "edit_sents_percent": 31.74 } } }, { "session_id": 7, "author_id": "olly666", "author_conf": 20, "author_name": "Olly", "timestamp": "2015-07-02 18:53:59.565720", "requires_revision": true, "revised": false, "revised_at": null, "revised_by_id": null, "revised_by_name": null, "revised_via": null, "revised_in_session_id": null, "edit_stats": { "en": { "edit_sents": 3, "edit_sents_percent": 2.58 } } } ] }
/text/revisions
Returns a list of all edit sessions for all API user’s document files that are pending to be revised.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/text/revisions?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"document_id": <str>,
"session_id": <int>,
"author_id": <str>,
"author_conf": <int>,
"author_name": <str>,
"timestamp": <str>,
"edit_stats": <dict>
},
...
]
document_id:<str>
|
Document ID. |
session_id:<str>
|
Session ID. |
author_id:<str>
|
Author ID owner of the session. |
author_conf:<int>
|
Confidence level of the author, from 0 to 100. |
author_name:<str>
|
Author name. Can be |
timestamp:<str>
|
Session end timestamp. |
edit_stats:<dict>
|
Dictionary containing statistics of the session’s edits. Each dictionary key is a language code (ISO-639-1) whose value is another dictionary that contains edit statistics of the corresponding translation. These dictionaries feature the following keys:
|
Output Examples
[ { "document_id": "DOCUMENT-ID-1234", "session_id": 8, "author_id": "jsnow21", "author_conf": 90, "author_name": "John Snow", "timestamp": "2015-07-04 21:23:07.000031", "edit_stats": { "en": { "edit_sents": 1, "edit_sents_percent": 1.97 } } } ]
/text/mark_revised
Mark/unmark an edition session as revised.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Document ID. |
|
session_id |
int |
Yes |
Session ID |
8 |
author_id |
str |
Yes |
Author ID, authorised by the API client, who revised the changes made in the Session ID session_id. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author. Must be |
|
revision_session_id |
int |
No |
Session ID under which the given Author ID revised the changes made in the Session ID session_id. |
12 |
unmark |
int |
No |
Do the inverse process: delete revised mark.
|
1 |
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/mark_revised?id=DOCUMENT-ID-1234&session_id=8&author_id=lord_stark1&author_conf=100&revision_session_id=12&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode" : <int> ,
"rcode_description" : <str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode": 0, "rcode_description": "Session ID marked as revised." }
/text/accept
Accept modifications of one or more pending edit sessions without having to revise them. Modifications are commited into the corresponding translation files.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Comma-separated list of Session IDs whose edits are meant to be accepted by the given Author ID. |
|
author_id |
str |
Yes |
Author ID, authorised by the API client, who revised the changes made in the Session ID session_id. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author. Must be |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/accept?id=27,43,82,121&&author_id=lord_stark1&author_conf=100&revision_session_id=12&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
Returns a list of dictionaries, one for each Session ID.
[
{
"session_id": <int>,
"rcode" : <int> ,
"rcode_description" : <str>
},
...
]
session_id:<int>
|
Session ID. |
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
[ { "rcode_description": "Session ID does not exist.", "rcode": 1, "session_id": 27 }, { "rcode_description": "Session ID did not require revision.", "rcode": 4, "session_id": 43 }, { "rcode_description": "Session ID already revised.", "rcode": 5, "session_id": 82 }, { "rcode_description": "Changes from Session ID successfully accepted.", "rcode": 0, "session_id": 121 } ]
/text/reject
Reject modifications of one or more pending edit sessions without having to revise them.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Comma-separated list of Session IDs whose edits are meant to be accepted by the given Author ID. |
|
author_id |
str |
Yes |
Author ID, authorised by the API client, who revised the changes made in the Session ID session_id. |
|
author_name |
str |
No |
Author Name |
|
author_conf |
int |
Yes |
Confidence level of the author. Must be |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
expire |
int |
No |
Expiration date UNIX timestamp of the request (seconds since 01-01-1970 in UTC to the expiration date). Required only if |
|
http://my-tlp-server.com/api/text/reject?id=27,43,82,121&&author_id=lord_stark1&author_conf=100&revision_session_id=12&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
Returns a list of dictionaries, one for each Session ID.
[
{
"session_id": <int>,
"rcode" : <int> ,
"rcode_description" : <str>
},
...
]
session_id:<int>
|
Session ID. |
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
[ { "rcode_description": "Session ID does not exist.", "rcode": 1, "session_id": 27 }, { "rcode_description": "Session ID did not require revision.", "rcode": 4, "session_id": 43 }, { "rcode_description": "Session ID already revised.", "rcode": 5, "session_id": 82 }, { "rcode_description": "Changes from Session ID successfully rejected.", "rcode": 0, "session_id": 121 } ]
Appendix G: Web Service API: /web API specifications
Please note that all the following interfaces will share a common prefix: /web.
|
/manage
|
Features four sub-interfaces to list, add, edit and delete websites. |
|
/systems
|
Get a list of all available Machine Translation systems that can be applied to translate a document file. |
|
/getjs
|
Returns a JavaScript plugin that enables web translation on web browsers. |
|
/translate
|
Requests translations of a given set of texts, sending part or all of them to translate if no translations are available yet. |
|
/amend
|
Send user corrections of translated texts. |
|
/editor
|
Features three sub-interfaces: /langs, /get and /mod. |
/web/manage
This interface allows the client to manage all web sites registered on TLP.
The /manage interface is split into the following four sub-interfaces:
Every sub-interface has different input specifications, please refer to each sub-section.
/web/manage/list
List all user’s websites.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/web/manage/list?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
{
"name": <str>,
"language": <str>,
"key": <str>,
"active": <bool>,
"url_pattern": <str>,
"options": <dict>
},
...
]
name:<str>
|
Website name |
language:<str>
|
Website’s source language code (ISO-639-1). |
key:<str>
|
Website key. |
active:<bool>
|
Tells whether a website is active (new text contents are sent to be translated) or not. |
url_pattern:<str>
|
URL pattern: only website’s pages that match the pattern are translated. |
options:<dict>
|
JSON dictionary with website options, such as languages to which the website has to be translated. |
Output Examples
[ { "name": "www.mllp.upv.es", "language": "en", "key": "bf6fc9bfc04f752047f7b932fedc861e", "active": true, "url_pattern": "www.mllp.upv.es", "options": { "requested_langs": { "fr": { "sid": 42 }, "sl": { "sid": 50 }, "ca": { "sid": 10 }, "es": { "sid": 27 }, "it": { "sid": 37 } } } } ]
/web/manage/add
Add/register a new website.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
name |
str |
Yes |
Website name. |
|
language |
str |
Yes |
Website source language code (ISO 639-1). |
|
url_pattern |
str |
Yes |
URL Pattern. Only those URLs that match the given pattern are sent to be translated. Supported wildcard patterns: *. |
|
requested_langs |
dict |
Yes |
JSON dictionary defining languages to which the website will be translated. Please refer to Requesting translation languages, "requested_langs" option. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/web/manage/add?name=MLLP&language=en&url_pattern=www.mllp.upv.es&requested_langs=%7B%22es%22%3A%7B%7D%2C%22ca%22%3A%7B%22sid%22%3A27%7D%7D&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode":<int> ,
"rcode_description":<str>,
"id":<str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
id:<str>
|
Website key, that will be required by other interfaces to identify the website. |
Output Examples
{ "rcode":0, "rcode_description":"New website successfully added", "id":"bf6fc9bfc04f752047f7b932fedc861e" }
/web/manage/edit
Edit an existing website.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Website key. |
|
enabled |
bool |
No |
Enable/Disable translation of new contents for this website. |
|
url_pattern |
str |
No |
URL Pattern. Only those URLs that match the given pattern are sent to be translated. Supported wildcard patterns: *. |
|
requested_langs |
dict |
No |
JSON dictionary defining languages to which the website will be translated. Please refer to Requesting translation languages, "requested_langs" option. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/web/manage/edit?id=bf6fc9bfc04f752047f7b932fedc861e&enabled=false&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode":<int> ,
"rcode_description":<str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode":0, "rcode_description":"Website successfully edited" }
/web/manage/delete
Delete an existing website. This action can only be performed by admin API users.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Website key. |
|
purge |
bool |
No |
Delete and purge all website contents. By default, manually supervised translations are preserved ( |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/web/manage/delete?id=bf6fc9bfc04f752047f7b932fedc861e&purge=true&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode":<int> ,
"rcode_description":<str>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
Output Examples
{ "rcode":0, "rcode_description":"Website successfully deleted" }
/web/editor
This interface is called by the TLP Web Translation Editor and it is split into the following three sub-interfaces:
Every sub-interface has different input specifications, please refer to each sub-section.
/web/editor/langs
Returns a list of translation languages available for a specific website.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Website key. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/web/editor/langs?id=bf6fc9bfc04f752047f7b932fedc861e&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode":<int> ,
"rcode_description":<str>,
"web_lang_code":<str>,
"web_lang_name":<str>,
"langs": [
{
"lang_code":<str>,
"lang_name":<str>
},
...
]
}
rcode:<int>
|
Return code.
|
web_lang_code:<str>
|
Language code (ISO-639-1) of the document language. |
web_lang_name:<str>
|
Language name of the document language. |
langs:<list:dict>
|
List of languages available.
|
Output Examples
{ "rcode_description": "Returning language list", "rcode": 0, "web_lang_code": "en", "web_lang_name": "English", "langs": [ { "lang_code": "fr", "lang_name": "Français" }, { "lang_code": "ca", "lang_name": "Català" }, { "lang_code": "it", "lang_name": "Italiano" }, { "lang_code": "sl", "lang_name": "Slovene" }, { "lang_code": "es", "lang_name": "Español" } ] }
/web/editor/get
Returns all existing source texts or translations of a specific website.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Website key. |
|
language |
str |
Yes |
Language code (ISO 639-1). |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
en) texts (GET with multiple parameters).http://my-tlp-server.com/api/web/editor/get?language=en&id=bf6fc9bfc04f752047f7b932fedc861e&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bes) translations (GET with multiple parameters).http://my-tlp-server.com/api/web/editor/get?language=es&id=bf6fc9bfc04f752047f7b932fedc861e&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode":<int> ,
"rcode_description":<str>,
"texts":<dict>
}
rcode:<int>
|
Return code.
|
texts:<dict>
|
JSON dictionary of text hashes and text contents.
|
Output Examples
{ "rcode_description": "Returning texts", "rcode": 0, "texts": { "dcbe226b3510c277e9fe42f89f179f6e": { "status": null, "text": "See larger map", "added": "2016-05-31 14:31:49.340621", "last": "2016-06-21 12:33:58.247419" }, "8f9bfe9d1345237cb3b2b205864da075": { "status": null, "text": "User", "added": "2016-06-02 11:33:45.780144", "last": "2016-06-29 20:23:38.410331" } } }
{ "rcode_description": "Returning texts", "rcode": 0, "texts": { "dcbe226b3510c277e9fe42f89f179f6e": { "status": "revised", "text": "Ver mapa más grande", "added": null, "last": "2016-07-08 11:01:30.205199" }, "8f9bfe9d1345237cb3b2b205864da075": { "status": "automatic", "text": "Usuario", "added": null, "last": "2016-06-02 11:37:02.346747" } } }
/web/editor/mod
Updates text translations of a specific website and language.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
id |
str |
Yes |
Website key. |
|
language |
str |
Yes |
Language code (ISO 639-1). |
|
text |
dict |
Yes |
Dictionary of text hashes and supervised translations. |
|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
es) translation (GET with multiple parameters).http://my-tlp-server.com/api/web/editor/mod?text=%7B%220321c2c507c5b21377a6bad5bbcd6ec2%22%3A%22Esto%20es%20un%20texto%20traducido%20y%20corregido%22%7D&language=es&id=bf6fc9bfc04f752047f7b932fedc861e&user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
{
"rcode":<int> ,
"rcode_description":<str>,
"translations":<int>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
translations:<int>
|
Number of translations modified. |
Output Examples
{ "rcode":0, "rcode_description":"Updated 1 translations.", "translations": 1 }
/web/systems
Get a list of all available MT Systems that can be applied to translate webpages.
Input
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
user |
str |
Yes |
TLP Username / API Username. |
|
auth_token |
str |
Yes |
Authentication token for the provided |
|
http://my-tlp-server.com/api/web/systems?user=tluser&auth_token=edbab44c3a3f1ca8db4de8277a3bOutput
[
"mt": [
{
"source_lang": <str>,
"target_lang": <str>,
"id": <int>,
"name": <str>,
"description": <str>
},
...
]
]
mt:<list:dict>
|
List of all available Machine Translation Systems.
|
|
|
The system ID might be used to explicitly request to the Ingest Service the application of a particular MT system. For further information please see Requesting Subtitle Languages). |
Output Examples
{ "mt": [ { "source_lang": "ca", "target_lang": "es", "id": 14, "name": "Catalan-Spanish MT System", "description": "" }, { "source_lang": "es" "target_lang": "ca", "id": 11, "name": "Spanish-Catalan MT System", "description": "" }, { "source_lang": "en", "target_lang": "es", "id": 73, "name": "English-Spanish MT System", "description": "" }, { "source_lang": "es" "target_lang": "en", "id": 24, "name": "Spanish-English MT System", "description": "" } ] }
/web/getjs
Generates a JavaScript plugin that enables the translation of a given website on the client-side (on web browsers). This interface should be called by the client web browser when importing the JS plugin.
Input
This interface only supports GET requests.
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
key |
str |
Yes |
Website key. |
|
http://my-tlp-server.com/api/web/getjs?key=bf6fc9bfc04f752047f7b932fedc861eIn order to translate all website’s pages, these pages must include, inside the <header> tag, a <script> tag
with the src parameter pointing to this interface. Example:
<header> <script src="http://my-tlp-server.com/api/web/getjs?key=bf6fc9bfc04f752047f7b932fedc861e"></script> </header>
/web/translate
Requests translations of a given set of texts, sending part or all of them to translate if no translations are available yet. This interface is called by the JavaScript plugin generated by the /web/getjs interface.
Input
This interface only supports POST requests.
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
key |
str |
Yes |
Website key. |
|
language |
str |
Yes |
Translation language code (ISO 639-1). |
|
text |
dict |
Yes |
Dictionary of text hashes and text contents. |
|
Output
{
"rcode":<int> ,
"rcode_description":<str>,
"translations":<dict>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
translations:<dict>
|
Dictionary of text hashes and translated text contents. |
Output Examples
{ "rcode":0, "rcode_description":"Returning available translations.", "translations": { "0321c2c507c5b21377a6bad5bbcd6ec2":"Esto es un texto traducido" } }
/web/amend
Sends user corrections of translated texts. This interface is called by the JavaScript plugin generated by the /web/getjs interface.
Input
This interface only supports POST requests.
| Parameter name | Type | Required | Description | Example |
|---|---|---|---|---|
key |
str |
Yes |
Website key. |
|
language |
str |
Yes |
Translation language code (ISO 639-1). |
|
text |
dict |
Yes |
Dictionary of text hashes and supervised translations. |
|
pass |
str |
Yes |
MD5 hash of API user’s password. |
|
Output
{
"rcode":<int> ,
"rcode_description":<str>,
"translations":<int>
}
rcode:<int>
|
Return code.
|
rcode_description:<str>
|
Description of the return code (rcode). |
translations:<int>
|
Number of translations modified. |
Output Examples
{ "rcode":0, "rcode_description":"Updated 1 translations.", "translations": 1 }
Appendix H: Generating a Request Key
The request key is an alternative authentication method for the TLP Web Service that avoids revealing the API secret key of the client in the requests to the Web Service. This method can be used only with a reduced subset of Web Service interfaces (see Web Service API Specification Preface).
A request key depends on the values of some call parameters, and therefore it has to be explicitly generated for each API call.
The request key token is divided in two parts. The first part - the basic request key - is mandatory for all interfaces, while the second part is needed only when calling the /mod interface. Both parts are SHA-1 sums of a string composed by the concatenation of different call parameters plus the user’s API secret key. The concatenation of both key parts becomes the full request key.
On the one hand, the first part (basic request key) consists of the SHA-1 sum (40 bytes length) of:
-
idAPI call parameter -
expireAPI call parameter -
userAPI call parameter -
User’s secret key.
SHA-1 (id + expire + user + secret_key)On the other hand, the second part is the SHA-1 sum (40 bytes length) of:
-
author_idAPI call parameter -
author_confAPI call parameter -
expireAPI call parameter -
userAPI call parameter -
User’s secret key.
SHA-1 (author_id + author_conf + expire + user + secret_key)The full request key (80 bytes length) is the concatenation of both parts:
SHA-1 (id + expire + user + secret_key ) + SHA-1 (author_id + author_conf + expire + user + secret_key)It is important to note that all Web Service interfaces will read only the first part (the first 40 bytes, ignoring the remaining bytes) of the request key, except the /mod one that requires the full request key.
Input parameters:
id = media-1234
expire = 1433875891
user = tluser
author_id = player_user_1234
author_conf = 100
secret_key = mhes28gfj7vfdg7ylnpapom26ksjfyvjmsoeFirst part (Basic request key):
SHA-1 (id + expire + user + secret_key)SHA-1 (media-12341433875891tlusermhes28gfj7vfdg7ylnpapom26ksjfyvjmsoe)0cce9cd1c2a0f8d4cd1486bc317c24cb137fbf58Second part:
SHA-1 (author_id + author_conf + expire + user + secret_key)SHA-1 (player_user_12341001433875891tlusermhes28gfj7vfdg7ylnpapom26ksjfyvjmsoe)5ff4dec6d50b3aac13f3d0a7de4e3bb111bc107dFull request key:
0cce9cd1c2a0f8d4cd1486bc317c24cb137fbf585ff4dec6d50b3aac13f3d0a7de4e3bb111bc107dAppendix I: Python Commandline Utilities
TLP offers two useful Python command-line scripts to interact with the TLP
Server. These scripts are ws-client.py, tx-editor-url-generator.py, player-url-generator.py, tl-editor-url-generator.py and
web-tl-editor-url-generator.py. All them require the
libtlp python library, as well as a configuration file
properly set up.
On the client tools package, all this files are located at:
client-tools/python/scr/ws-client.py
client-tools/python/scr/tx-editor-url-generator.py
client-tools/python/scr/player-url-generator.py
client-tools/python/scr/tl-editor-url-generator.py
client-tools/python/scr/web-tl-editor-url-generator.py
client-tools/python/scr/config.iniConfiguration File
Both scripts requires a configuration file (config.ini) properly set up in order to work.
Each parameter of the configuration file is detailed below.
- web_service_url = <str>
-
Base URL location of the TLP Web Service.
- player_url = <str>
-
Base URL location of the TLP Media Player.
- translation_editor_url = <str>
-
Base URL location of the TLP Translation Editor.
- web_translation_editor_url = <str>
-
Base URL location of the TLP Web Translation Editor.
- enabled = <bool>
-
Enable or disable HTTP Authentication.
- username = <str>
-
HTTP Auth username.
- password = <str>
-
HTTP Auth Password.
- username = <str>
-
TLP username / API username.
- secret_key = <str>
-
API Secret Key Authentication Token.
- url_lifetime = <int>
-
Time slot, starting from the generation of the URL, in which the user will be allowed to access the Player/Editor (expire input parameter).
- user_id = <user_id>
-
Client-side user ID of the user who will edit the subtitles/translations (author_id input parameter).
- user_full_name = <user_full_name>
-
Client-side user name of the user who will edit the subtitles/translations (author_name input parameter). (optional)
- user_confidence = <user_confidence>
-
Confidence level of the above user (author_conf input parameter).
[general] web_service_url = http://my-tlp-server.com/api player_url = http://my-tlp-server.com/player translation_editor_url = http://my-tlp-server.com/editor [http_auth] enabled = no username = password = [api_client_auth] username = tluser secret_key = akjsfd982323098qwjs209823id09321io3290d request_key_expire_lifetime = 1440 [player_user_info] user_id = jsnow21 user_full_name = John Snow user_confidence = 100
By default, both scripts will attempt to load a configuration file named
config.ini from the same script directory. You can provide an alternative configuration
file location with the --config-file option. The option --print-sample-config-file
prints a sample config file to the standard output.
ws-client.py
ws-client.py is a Python command-line utility that interacts with the TLP Web Service API. It can perform queries to all Web Service interfaces. The configuration file has to be properly set up in order to work.
-
libtlp Python Library (included in the TLP Client Tools Package).
usage: ws-client.py [-h] [-d] [-V] [-g] [-D] [-c <file>] [-C]
[-I <user_tuple>] [-k] [-K REQUEST_KEY_LIFETIME]
[-B <username>] [-f <dest>]
{speech,text,web} ...
****** TLP Web Service API client tool *******
This script makes use of the TLP Python Library (libtlp.py) and features almost
all of TLP Web Service's interfaces, accessible using commands and sub-commands
that are named as the paths of the corresponding interfaces.
More precisely, commands correspond to the sub-APIs featured by the Web
Service, while sub-commands are the paths defined by the interfaces implemented
by each sub-API.
For instance, to call the /speech/ingest/new interface, you just have to call
this script setting the corresponding (and trivial) sequence of commands and
sub-commands:
python ws-client.py speech ingest new (...)
Every command and sub-command have specific arguments and options. You can
check them easily adding the -h (--help) option after the command or
sub-command.
We recommend to check the complete API specifications in the TLP documentation
available on-line at http://www.mllp.upv.es/tlp or inside the TLP package at
doc/index.html.
optional arguments:
-h, --help show this help message and exit
-d, --debug Print debug information
-V, --development-mode
Enable development mode
-g, --use-get-query Use GET HTTP queries instead of POST when possible
-D, --use-data-param Use a single base64-encoded JSON 'data' GET parameter
instead of multiple GET parameters
-c <file>, --config-file <file>
Config file. Default: config.ini
-C, --print-sample-config-file
Print sample config file and exit
-I <user_tuple>, --api-client-auth <user_tuple>
API client user name and authentication token, in the
following format: USERNAME:AUTH_TOKEN. Default: from
config file.
-k, --use-request-key
Use request-key as auth_token instead of secret_key.
-K REQUEST_KEY_LIFETIME, --request-key-lifetime REQUEST_KEY_LIFETIME
Set request key lifetime in minutes. Default: from
config file.
-B <username>, --su <username>
su (substitute user) option: specify username. Only
for admin users.
-f <dest>, --store-output-file <dest>
Store the Web Service response in a file.
Available Commands (Web Service's sub-APIs):
The Web Service implements three sub-APIs for the three main classes of objects than can be processed by TLP.
These sub-APIs are implemented in this script and accessible by their respective commands.
{speech,text,web}
speech /speech API: is aimed to deal with video and audio
files.
text /text API: is intended to deal with text documents and
contents.
web /web API: is intended to specifically deal with text
contents extracted from html documents from the client
(web browser) side.This script makes use of the TLP Python Library and features almost all of TLP Web Service’s interfaces, accessible using commands and sub-commands that are named as the paths of the corresponding interfaces.
More precisely, commands correspond to the sub-APIs featured by the Web Service, while sub-commands are the paths defined by the interfaces implemented by each sub-API.
For instance, to call the /speech/ingest/new interface, you just have to call this script setting the corresponding sequence of commands and sub-commands:
python ws-client.py speech ingest new (...)Every command and sub-command have specific arguments and options. You can check them easily adding the -h (--help) option after the command or sub-command. For instance:
python ws-client.py speech -h
python ws-client.py speech ingest -h
python ws-client.py speech ingest new -hpython ws-client.py speech ingest new -l "en" -t "My first video" -M "/path/to/my/video.mp4" -p en -p es "1234"python ws-client speech status "up-1234"python ws-client.py speech langs "1234"python ws-client.py speech get -f "srt" "1234" "en"player-url-generator.py
player-url-generator.py is a Python command-line utility that generates valid URL links to the TLP Player according to these specifications. The configuration file has to be properly set up in order to work.
-
libtlp Python Library (included in the TLP Client Tools Package).
usage: player-url-generator.py [-h] [-d] [-C] [-c <file>] [-s START_TIME]
[-l LANGUAGE] [-S SESSION_ID] [-t TIME_SLOT]
[-a AUTHOR_ID] [-n AUTHOR_NAME]
[-k AUTHOR_CONF] [-I <user_tuple>]
media_id
player-url-generator.py: Generate valid URLs for calling the TLP Player.
positional arguments:
media_id Media ID
optional arguments:
-h, --help show this help message and exit
-d, --debug Print debug information
-C, --print-sample-config-file
Print sample config file and exit
-c <file>, --config-file <file>
Config file. Default: config.ini
-s START_TIME, --start-time START_TIME
Start time in seconds.
-l LANGUAGE, --language LANGUAGE
Subtitles language.
-S SESSION_ID, --session-id SESSION_ID
Review subtitle modifications made under the given
Session ID.
-t TIME_SLOT, --time-slot TIME_SLOT
Time slot for editing in minutes. Default: from config
file.
-a AUTHOR_ID, --author-id AUTHOR_ID
Author ID ('author_id'). Default: from config file.
-n AUTHOR_NAME, --author-name AUTHOR_NAME
Author Name. Default: from config file.
-k AUTHOR_CONF, --author-conf AUTHOR_CONF
Author confidence level [0-100]. Default: from config
file.
-I <user_tuple>, --api_user <user_tuple>
User name and authentication token, in the following
format: USERNAME:AUTH_TOKEN. Default: from config
file.player-url-generator.py call: Get URL for editing English subtitles of a given media ID:--$ player-url-generator.py -l en MEDIA-ID-1234tl-editor-url-generator.py
tl-editor-url-generator.py is a Python command-line utility that generates valid URL links to the TLP Translation Editor according to these specifications. The configuration file has to be properly set up in order to work.
-
libtlp Python Library (included in the TLP Client Tools Package).
usage: tl-editor-url-generator.py [-h] [-d] [-C] [-c <file>] [-S SESSION_ID]
[-t TIME_SLOT] [-a AUTHOR_ID]
[-n AUTHOR_NAME] [-k AUTHOR_CONF]
[-I <user_tuple>]
media_id language
player-url-generator.py: Generate valid URLs for calling the TLP Player.
positional arguments:
media_id Media ID
language Translation language.
optional arguments:
-h, --help show this help message and exit
-d, --debug Print debug information
-C, --print-sample-config-file
Print sample config file and exit
-c <file>, --config-file <file>
Config file. Default: config.ini
-S SESSION_ID, --session-id SESSION_ID
Review subtitle modifications made under the given
Session ID.
-t TIME_SLOT, --time-slot TIME_SLOT
Time slot for editing in minutes. Default: from config
file.
-a AUTHOR_ID, --author-id AUTHOR_ID
Author ID ('author_id'). Default: from config file.
-n AUTHOR_NAME, --author-name AUTHOR_NAME
Author Name. Default: from config file.
-k AUTHOR_CONF, --author-conf AUTHOR_CONF
Author confidence level [0-100]. Default: from config
file.
-I <user_tuple>, --api_user <user_tuple>
User name and authentication token, in the following
format: USERNAME:AUTH_TOKEN. Default: from config
file.tl-editor-url-generator.py call: Get URL for editing English subtitles of a given media ID:--$ tl-editor-url-generator.py -l en MEDIA-ID-1234web-tl-editor-url-generator.py
web-tl-editor-url-generator.py is a Python command-line utility that generates valid URL links to the TLP Web Translation Editor according to these specifications. The configuration file has to be properly set up in order to work.
-
libtlp Python Library (included in the TLP Client Tools Package).
usage: web-tl-editor-url-generator.py [-h] [-d] [-C] [-c <file>]
[-t TIME_SLOT] [-I <user_tuple>]
web_key language
web-tl-editor-url-generator.py: Generate valid URLs for calling the TLP Web
Translation Editor.
positional arguments:
web_key Web Key
language Translation language.
optional arguments:
-h, --help show this help message and exit
-d, --debug Print debug information
-C, --print-sample-config-file
Print sample config file and exit
-c <file>, --config-file <file>
Config file. Default: config.ini
-t TIME_SLOT, --time-slot TIME_SLOT
Time slot for editing in minutes. Default: from config
file.
-I <user_tuple>, --api_user <user_tuple>
User name and authentication token, in the following
format: USERNAME:AUTH_TOKEN. Default: from config
file.web-tl-editor-url-generator.py call: Get URL for editing Spanish translations of a given website key:--$ wen-tl-editor-url-generator.py MYWEBKEY-1234 esAppendix J: DFXP Format Specification
This Appendix describes a format extension from the original DFXP format. This extension was made in order to reflect the needs of the transLectures EU project:
-
Confidence measures for automatic transcription and translations have to be reflected in the DFXP document.
-
Track needs to be kept of all subtitle edits made by human users, starting from an automatic transcription/translation.
For this purpose, new XML tags have been proposed. These tags belong to a new namespace called tl. Therefore, these new XML tags will be something like <tl:XXX>, where tl is the namespace and XXX is the tag. The root <tt> element has been extended in this way:
<tt xml:lang="en" xmlns="http://www.w3.org/2006/04/ttaf1" xmlns:tts="http://www.w3.org/2006/10/ttaf1#style" xmlns:tl="translectures.eu">
The MLLP research group launched with TLP 1.2 an updated version of the DFXP format, namely DFXP v1.1, which enables the modification of the speech segmentation. The counterpart is that user edition history cannot be tracked inside the DFXP file.
DFXP Tags
Tags are defined at four levels: document, segment, group and word. Document tags are located at the head section, while segment, group and word tags are located at the body section. An additional tag to relate alternative transcriptions/translations is also included. A detailed explanation of tags follows:
-
<tl:document>: This tag defines the attributes of the transcription/translation at the top level. As the attributes are inherited, the value of the attributes defined here are the default values, unless otherwise redefined. It contains a specific attribute to associate the current file to a unique video ID. Abbreviation: <tl:d>.
-
<tl:current>: This tag defines the current status of the subtitle file with the last modifications made by users, it contains an ordered sequence of text segments or captions. Abbreviation: <tl:c>.
-
<tl:origin>: This tag defines the former status of the subtitle file (typically the automatic transcription/translation), it contains an ordered sequence of text segments or captions. Abbreviation: <tl:o>.
-
<tl:segment>:This tag defines text segments or captions. Abbreviation: <tl:s>
-
<tl:group>: This tag defines a group of words inside a segment. This tag will usually appear as a result of the interaction with the user. Abbreviation: <tl:g>
-
<tl:word>: A simple tag used to specify single word properties, mostly used for time alignments and confidence measures. Other attributes are generally inherited. Abbreviation: <tl:w>
Next, we define the set of attributes related to the tags just defined. Most of the attributes are applicable to all levels:
-
authorType: Type of author. Their values are automatic or human. Human for those transcriptions/translations generated by human experts or completely supervised by human experts. Automatic for those transcriptions/translations fully generated by an ASR/MT system. Abbreviation: aT.
-
authorId: Author identifier. For example: RWTH, XEROX, UPV, Maria Gialama, etc. Abbreviation: aI.
-
authorConf: Confidence measure of the author when the authorType is human. This attribute is coupled with an authorId. This tag could be useful for non-native users supervising a foreign language. Abbreviation: aC.
-
wordSegId: It identifies the system that performs the automatic segmentation at the word level. It could be different from the authorId, since groups of words supervised by the user may be segmented at the word level with a different system from that providing the automatic transcription. Abbreviation: wS.
-
timeStamp: Instant of creation or modification. The timestamp format is a combination of date and time of day in Chapter 5.4 of ISO 8601. The format is [-]CCYY-MM- DDThh:mm:ss[Z$|$(+$|$-)hh:mm]. Abbreviation: tS.
-
confMeasure: Confidence measure of the level. These values are generated by ASR and MT systems. Abbreviation: cM.
-
videoId: Tag only defined at the document level. It links the current transcription or translation DFXP file to a unique video. Abbreviation: vI.
-
segmentId: It is used to uniquely identify a segment in a transcription or translation file. As mentioned above, alternative segments have the same segmentId. Abbreviation: sI.
-
begin: Instant of the beginning of an audio portion of the current tag in seconds. Abbreviation: b.
-
end: Instant of the end of an audio portion of the current tag in seconds. Abbreviation: e.
-
elapsedTime: Processing time. Abbreviation: eT.
-
modelID: Model used by decoder. Abbreviation: mI.
-
processingSteps: Processing steps of decoder. Abbreviation: pS.
-
audioLength: Complete length of the video. Abbreviation: aL.
-
status: Supervision status of the subtitles. Abbreviation: st. Possible values:
-
fully_automatic → All segments are automatic.
-
partially_human → Some segments have been supervised.
-
fully_human → All segments have been supervised.
-
|
|
Special characters such as & “ < > ' must be escaped in the DFXP files according to the XML standard (see http://xml.silmaril.ie/specials.html). |
Examples of Extended DFXP Tags
Examples at <head>
<tl:d aT="automatic" aI="UPV-v1.0" tS="2012-10-03T21:32:52" aC="0.6" cM="0.75" vI="1234-abcd" b="0.0" e="400.6"/> <tl:d aT="human" aI="John Doe" tS="2012-10-03T21:32:52" aC="1.0" cM="1.0" videoId="1234-abcd" b="1.0" e="400.6"/>
Examples at <body>
<tl:s sI="1" aT="automatic" aI="UPV" wS="UPV" tS="2012-10-03T21:32:52" cM="0.62" aC="0.5" b="0.0" e="15.6"> i am very hungry with you </tl:s>
<tl:g aT="human" aI="John Doe" aC="0.75" tS="2012-10-03T21:32:52" cM="1.0" b="2.7" e="3.5"> the way we train in IBM </tl:g>
<tl:w aT="automatic" aI="UPV" aC="0.5" cM="0.61" tS="2012-10-03T21:32:52" cM="1.0" b="1.3" e="2.1">the</tl:w> <tl:w cM="1.3" b="1.6" e="2.1">way</tl:w>
Use cases
-
A transcription/translation is automatically generated by an automatic system creating a DFXP file from scratch.
-
A transcription/translation is manually generated by a human expert creating a new DFXP file.
-
A user supervises an automatic/manual transcription/translation.
Use case examples
<?xml version="1.0" encoding="utf-8"?> <tt xml:lang="en" xmlns="http://www.w3.org/2006/04/ttaf1" xmlns:tts="http://www.w3.org/2006/10/ttaf1#style" xmlns:tl="translectures.eu"> <head> <tl:d aT="automatic" aI="UPV-v1.0" wS="UPV-v1.0" tS="2012-10-03T21:32:52" aC="0.56" cM="0.75" videoId="00505-Profesores_Alcoy.M03.B01" b="0.0" e="12.50"/> </head> <body> <tl:c> <tl:s sI="1" cM="0.75" b="0.00" e="3.20"> <tl:w cM="0.85" b="0.00" e="0.75">most</tl:w> <tl:w cM="0.89" b="0.75" e="0.95">of</tl:w> <tl:w cM="0.63" b="0.95" e="1.15">you</tl:w> <tl:w cM="0.40" b="1.15" e="1.35">are</tl:w> <tl:w cM="0.90" b="1.35" e="1.50">probably</tl:w> <tl:w cM="0.85" b="1.50" e="1.75">ventured</tl:w> <tl:w cM="0.55" b="1.75" e="2.00">the </tl:w> <tl:w cM="0.98" b="2.00" e="2.75">problem</tl:w> <tl:w cM="0.60" b="2.75" e="3.20">that</tl:w> </tl:s> <tl:s sI="2" cM="0.19" b="8.50" e="12.50"> <tl:w cM="0.1" b="8.50" e="9.00">To</tl:w> <tl:w cM="0.2" b="9.00" e="10.00">solve</tl:w> <tl:w cM="0.1" b="10.00" e="10.70">on</tl:w> <tl:w cM="0.1" b="10.70" e="12.50">this</tl:w> </tl:s> </tl:c> <tl:o> <tl:s sI="1" cM="0.75" b="0.00" e="3.20"> <tl:w cM="0.85" b="0.00" e="0.75">most</tl:w> <tl:w cM="0.89" b="0.75" e="0.95">of</tl:w> <tl:w cM="0.63" b="0.95" e="1.15">you</tl:w> <tl:w cM="0.40" b="1.15" e="1.35">are</tl:w> <tl:w cM="0.90" b="1.35" e="1.50">probably</tl:w> <tl:w cM="0.85" b="1.50" e="1.75">ventured</tl:w> <tl:w cM="0.55" b="1.75" e="2.00">the </tl:w> <tl:w cM="0.98" b="2.00" e="2.75">problem</tl:w> <tl:w cM="0.60" b="2.75" e="3.20">that</tl:w> </tl:s> <tl:s sI="2" cM="0.19" b="8.50" e="12.50"> <tl:w cM="0.1" b="8.50" e="9.00">To</tl:w> <tl:w cM="0.2" b="9.00" e="10.00">solve</tl:w> <tl:w cM="0.1" b="10.00" e="10.70">on</tl:w> <tl:w cM="0.1" b="10.70" e="12.50">this</tl:w> </tl:s> </tl:o> </body> </tt>
<?xml version="1.0" encoding="utf-8"?> <tt xml:lang="en" xmlns="http://www.w3.org/2006/04/ttaf1" xmlns:tts="http://www.w3.org/2006/10/ttaf1#style" xmlns:tl="translectures.eu"> <head> <tl:d aT="manual" aI="Maria" aC="1.0" videoId="00505-Profesores_Alcoy.M03.B01" tS="2012-10-03T21:32:52" cM="1.0" b="0.0" e="12.50"/> </head> <body> <tl:c> <tl:s sI="1" b="0.00" e="3.20"> most of you have probably ventured into the problem set. </tl:s> <tl:s sI="2" b="8.50" e="12.50"> The solution is: </tl:s> </tl:c> <tl:o> <tl:s sI="1" b="0.00" e="3.20"> most of you have probably ventured into the problem set. </tl:s> <tl:s sI="2" b="8.50" e="12.50"> The solution is: </tl:s> </tl:o> </body> </tt>
<?xml version="1.0" encoding="utf-8"?> <tt xml:lang="en" xmlns="http://www.w3.org/2006/04/ttaf1" xmlns:tts="http://www.w3.org/2006/10/ttaf1#style" xmlns:tl="translectures.eu"> <head> <tl:d aT="automatic" aI="UPV-v1.0" wS="UPV-v1.0" tS="2012-10-03T21:32:52" aC="0.56" cM="0.75" videoId="00505-Profesores_Alcoy.M03.B01" b="0.0" e="12.50"/> </head> <body> <tl:c> <tl:s sI="1" aT="human" aC="0.81" cM="1.0" aI="John" b="0.17" e="3.32" tS="2012-10-04T13:31:45"> most of you probably ventured into the problem set </tl:s> <tl:s sI="2" cM="0.19" b="8.5" e="12.50"> <tl:w cM="0.1" b="8.5" e="9">To</tl:w> <tl:w cM="0.2" b="9" e="10">solve</tl:w> <tl:w cM="0.1" b="10" e="10.7">on</tl:w> <tl:w cM="0.1" b="10.7" e="12.5">this</tl:w> </tl:s> </tl:c> <tl:o> <tl:s sI="1" cM="0.75" b="0.00" e="3.20"> <tl:w cM="0.85" b="0.00" e="0.75">most</tl:w> <tl:w cM="0.89" b="0.75" e="0.95">of</tl:w> <tl:w cM="0.63" b="0.95" e="1.15">you</tl:w> <tl:w cM="0.40" b="1.15" e="1.35">are</tl:w> <tl:w cM="0.90" b="1.35" e="1.50">probably</tl:w> <tl:w cM="0.85" b="1.50" e="1.75">ventured</tl:w> <tl:w cM="0.55" b="1.75" e="2.00">the </tl:w> <tl:w cM="0.98" b="2.00" e="2.75">problem</tl:w> <tl:w cM="0.60" b="2.75" e="3.20">that</tl:w> </tl:s> <tl:s sI="2" cM="0.19" b="8.50" e="12.50"> <tl:w cM="0.1" b="8.50" e="9.00">To</tl:w> <tl:w cM="0.2" b="9.00" e="10.00">solve</tl:w> <tl:w cM="0.1" b="10.00" e="10.70">on</tl:w> <tl:w cM="0.1" b="10.70" e="12.50">this</tl:w> </tl:s> </tl:o> </body> </tt>